距离计算在机器学习和科学计算中占据重要地位,尤其是在深度学习领域,点云处理、聚类分析以及最近邻搜索等任务中,计算高维空间中点之间的距离矩阵是基础且关键工作。PyTorch作为当前流行的深度学习框架,其torch.cdist功能提供了计算两个张量间成对距离的简便接口。但随着数据规模扩大和维度的提升,传统的torch.cdist实现面临严重的性能瓶颈。为了解决这一问题,使用Triton为torch.cdist提供高效实现成为一个备受关注的方案。Triton是由OpenAI开发的深度学习编译器工具,专注于编写GPU核函数以释放硬件性能。它允许开发者以相对简洁的Python风格代码编写高性能的GPU并行计算,从而替代复杂的CUDA代码。
利用Triton优化torch.cdist不仅可以显著提升计算速度,还支持梯度反向传播,非常适合训练过程中使用。torch.cdist函数主要计算两个张量x1和x2之间的距离矩阵,其实质是对每对样本计算p范数距离。默认p值为2,对应欧氏距离。传统PyTorch使用CUDA的内置核函数或CPU多线程实现,这在大规模数据时会受限于内存带宽和计算资源。Triton实现的优化版本通过充分利用GPU的并行计算能力和更合理的内存访问模式,有效减少了计算中的数据重复加载,并采用了块状分割策略使得线程块间协同计算,提高了吞吐率。实际使用中,用户只需通过pip安装第三方实现库,导入triton_cdist模块便可透明调用替代的opt_cdist实现,无需更改其他代码逻辑。
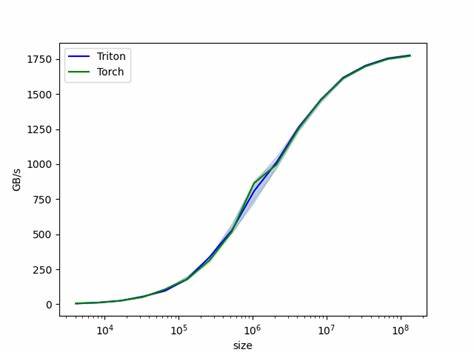
多维度的基准测试表明,Triton版本在处理小到中型规模(例如32到2048大小)的距离计算时,速度可提升到原torch.cdist数倍以上,尤其在p为1、2或10等不同范数条件下均表现优异。此性能提升随着数据规模增加表现趋于稳定,甚至在部分区间超过原生实现。该实现同样支持反向传播,是深度神经网络训练的理想选择。在准确性方面,Triton计算结果与原生torch.cdist保持高度一致,保障了科学计算的可信度。需要注意的是,目前批处理支持尚不够完善,对于包含批量维度的输入,只有广播处理生效,未来版本有望针对批量处理做更多优化。综合来看,使用Triton优化torch.cdist是提高距离计算效率的前沿解决方案,能广泛应用于点云匹配、图神经网络、嵌入空间距阵计算、聚类算法等领域。
在高维数据和大批量数据处理中尤其展现出优势,有效节约训练时间和算力资源。伴随着深度学习任务规模的不断增长,对于基础计算操作的加速需求也日益紧迫。Triton提供了灵活、高效和可扩展的核函数编写环境,助力开发者突破传统GPU计算框架的限制。torch.cdist的高性能替代实现为这一趋势树立了成功示范,未来在更多PyTorch核心算子的加速上极具潜力。对于机器学习工程师、研究人员以及深度学习框架开发者而言,深入学习和掌握Triton编程技巧,将极大提升模型训练和推理的效率。通过引入此类优化库,还能实现代码结构的简洁和可维护性,减少重复造轮子,集中精力在核心模型设计创新。
总之,Triton加速的torch.cdist方法是机器学习计算中的重要创新,代表着下一代高性能计算工具结合深度学习框架的趋势。它不仅解决了大规模距离矩阵计算的瓶颈,更为未来动态核函数编译与混合编程模式提供了宝贵经验。建议相关从业人员持续关注该技术的发展,积极尝试集成于实际项目中,推动AI算力效率的突破革新。