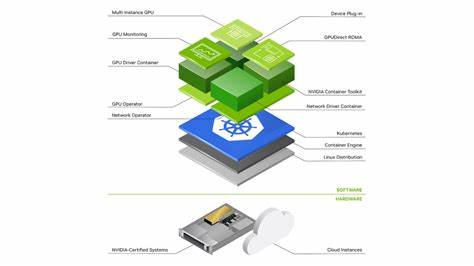
随着人工智能、大数据分析及高性能计算需求的飞速增长,GPU资源的高效利用成为企业和开发者关注的焦点。Kubernetes作为当前容器管理的主流平台,其扩展GPU资源的能力直接影响着应用性能和成本效益。然而,管理本地GPU基础设施不仅成本高昂,而且难以灵活应对突发需求。针对这一挑战,业界开始探索将GPU负载动态“云突发”(cloud bursting)至第三方GPU云平台的技术方案。其中,RunPod作为支持按需GPU计算的云平台,通过Virtual Kubelet实现与Kubernetes的无缝整合,成为解决这一痛点的领先实践。本文将全面剖析利用Virtual Kubelet实现Kubernetes GPU工作负载迁移至RunPod的原理、部署及应用,助力读者构建弹性、高效且经济的GPU计算环境。
Virtual Kubelet充当连接Kubernetes集群与RunPod云端GPU实例的虚拟节点,允许管理员将GPU工作负载直接调度到RunPod平台,而无需管理底层物理服务器。其核心优势在于动态扩展集群GPU容量,释放本地资源压力,同时根据预算自动调控使用的GPU类型和数量,实现真正的云端弹性。通过虚拟节点映射,RunPod上的GPU资源在Kubernetes视角下表现为原生节点,无缝参与调度和生命周期管理,大大简化了应用运维流程。 该方案的工作机制基于Virtual Kubelet Provider接口实现。首先,Virtual Kubelet在集群中注册虚拟节点,将RunPod的GPU容量作为集群可调度资源展现。用户创建GPU请求的Pod时,可以通过节点选择器和容忍配置将任务定向到虚拟节点。
此时,控制器调用RunPod API完成对应实例的创建和配置,随后持续监控任务状态,并同步回Kubernetes环境,确保任务执行状态与调度状态保持一致。任务完成后,控制器负责清理相关资源,保障成本最优化。 安装和配置过程简便高效。推荐方式为使用Helm Chart进行部署,支持通过RunPod API密钥进行身份验证。部署完成后,集群内将自动出现名为“virtual-runpod”的虚拟节点。用户在Pod配置文件中指定节点选择器“type: virtual-kubelet”及相应容忍,即可将GPU任务推送到RunPod。
通过注解功能,支持细粒度资源限制,如最低GPU显存要求、指定数据中心、模板ID等,实现灵活调度策略。此外,提供命令行参数和配置文件两种方式供用户定制调度频率、最大GPU价格等关键参数,进一步保障调度的灵活性和成本可控性。 监控方面,Virtual Kubelet控制器集成健康检查接口,包括存活和就绪探针,支持Kubernetes自带的监控工具。日志管理方便,用户可通过kubectl方便获取控制器运行日志及虚拟节点状态,便于故障排查和性能调优。虽然当前因RunPod API限制尚无法实现容器终端交互或日志直连,但整体Pod生命周期管理已经十分完善和稳定,为云端GPU容器工作负载的主流实践提供坚实基础。 从架构设计来看,项目采用Go语言开发,实现了高效、轻量且易扩展的控制器。
核心模块涵盖RunPod客户端通信、虚拟节点管理、Pod的状态同步及生命周期控制,保持了良好的模块化设计。支持单一或多数据中心部署,满足复杂企业级多云场景需求。更重要的是,成本优化机制通过限制GPU价格上限,让用户灵活把控云端投入,避免资源浪费。 然而,该技术方案仍有改进空间。例如目前不支持容器内交互式操作,限制了部分调试和维护流程;日志获取需通过RunPod平台间接实现,不够便利。此外,因为RunPod API本身的约束,部分高级功能如私有镜像认证或云类型选择尚处于实验性阶段。
随着API的完善和生态发展,未来将进一步丰富和强化这些功能。 整体而言,利用Virtual Kubelet连接Kubernetes和RunPod的GPU资源,实现了云原生GPU任务的动态扩展与调度自动化,极大提升了企业应对波动计算需求的能力。该方案助力开发者不必担心底层资源冗余和容量不足,专注于应用需求,享受简单、灵活、成本可控的GPU计算环境。 未来,随着AI、机器学习和高性能计算的持续爆发,云端GPU资源需求只会攀升。Virtual Kubelet与RunPod的结合为企业打造弹性、高效、经济的GPU计算平台提供了强有力的解决路径。期待更多社区贡献和产业合作推动该项目不断完善,助力开发者和运维人员开创更具竞争力的云计算新时代。
。