随着人工智能技术的迅猛发展,大语言模型(LLMs)在自然语言处理领域展现了巨大的潜力和应用价值。然而,在研究和应用过程中,学界和业界普遍发现,模型规模的不断扩大似乎面临着收益递减的困境,尤其是在处理长远任务时,模型的表现提升趋于缓慢甚至显得有限。这种现象引发了对大模型扩展价值的广泛讨论和质疑,许多人开始怀疑继续激进扩展模型规模是否值得投入巨大的资源成本。然而,最新的研究成果表明,这种收益递减的表象很可能是一种"幻象",它源自于评测和理解长任务执行能力方法的局限。从根本上说,单步任务的表现提升虽然看似微不足道,但其在多步任务中的累积效应能够带来指数级的性能提升。本文将深入剖析这一问题的本质,揭示执行能力如何成为长任务成功的关键,探讨大模型如何通过规模和执行策略的优化,实现对复杂长任务的有效驾驭。
传统的模型评估方法多依赖于单步准确率的度量,即模型在独立的简单任务或短任务上的表现。虽然这种评估简便直观,但却未能充分体现模型在长序列任务中的表现潜力。长序列任务本质上是多个步骤或动作的连续执行,其成功与否取决于每一步的准确率及其链式反应。事实证明,即使单步提升微小,也可能通过任务步数的累积转变为任务完成度的质的飞跃。换句话说,模型在短任务中表现平平,未必代表其在长任务中的能力有限。研究指出,很多时候大语言模型在长任务中出现失败,不是因为认知或推理能力不足,而是执行过程出现错误导致的链式崩溃。
这些错误在任务一步步延续时逐渐放大,形成"自我条件效应",即模型在后续步骤的输入中包含了自身之前的错误信息,从而加重误判的可能性。该效应令模型错误几率呈递增趋势,严重阻碍了实现多步骤任务的目标。令人意外的是,这种"自我条件效应"并不能靠单纯增大模型规模得到根本缓解。虽然规模大的模型在单步预测上能够达到更高的准确度,但当错误已进入上下文,模型仍然容易陷入错误轨迹而无法自我纠正。这一发现促使研究者将视角从"规模扩展"和"模型推理能力"转向了"执行能力"的本质问题。执行能力强调模型不仅要掌握知识和推理方法,更要能准确无误地按照预定计划执行多步操作。
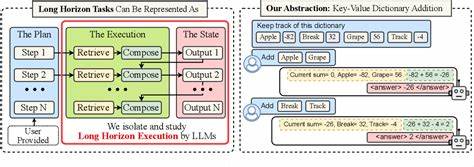
在这一框架下,研究者尝试为模型提供了详细的计划和相关知识,隔离了纯推理与执行两个环节,观察模型如何在明确指导下完成长远任务。实验结果显示,规模较大的模型在明确执行指令的前提下,能够胜任更多步骤的操作,即便小模型在单步准确度上几乎无误,也不及大模型完成长任务的能力。值得注意的是,通过所谓"思考"(或称为"链式思考"、"多步思维")机制,模型能够有效缓解自我条件效应带来的负面影响。思考过程允许模型在生成最终输出前,进行中间步骤的分解和检验,类似于人类的反复推理和自我校正。这样不仅提升了单步的准确率,也避免了错误累积造成的连锁反应。思考机制的引入使得模型在单次生成中能够处理更长更复杂的任务,突破了长上下文窗口的限制。
同时,思考也提升了模型的鲁棒性和灵活性,使得其在面对多步骤执行时表现更加稳定和可靠。未来的研究方向不但关注继续扩大模型规模,更加注重如何提升执行的连贯性与准确度。借助专项设计的执行测试集和长任务评测标准,科学地衡量模型在多步骤任务中的表现,为模型训练、人机交互以及实际应用提供更加精准的衡量依据。长远来看,实现高效的长任务执行能广泛催生诸多应用场景,包括复杂问题的多步推理、自动化工作流执行、编程问题的渐进解决以及大型项目的知识整合等。同时,对于爆炸性增长的算力需求,优化执行策略也意味着能够更有效地利用有限计算资源,实现性能和成本的双赢。总体而言,所谓的大语言模型收益递减的幻象源自评测视角的局限和任务设计的不合理。
在重新审视模型执行力的价值后,研究者发现规模扩展和思考机制协同作用下,模型具备了处理远超预期复杂度任务的潜力。通过优化执行流程、消解自我条件效应、强化思考机制,未来的大语言模型将能更加自如地驾驭长任务,推动人工智能在众多领域实现突破。同时,这一发现为长任务的设计与评估提供了科学依据,有望引领业界迈向更高效、更智能的交互新时代。 。