在计算机程序设计中,理解栈的内存结构和局部变量的布局对于优化代码性能、调试难题以及避免潜在的内存错误至关重要。许多编程初学者以及部分有经验的开发者都对“栈向下增长但局部变量向上排列”这一现象感到疑惑。本文将深入解析这一话题,通过简明的代码示例和原理讲解,帮助读者彻底明白栈内存及局部变量在内存中的布局方式。 首先,我们需要明确什么是栈。在现代计算机中,栈是一块为程序运行时管理局部变量和函数调用信息而设计的内存区域。它遵循后进先出(LIFO)的原则,能快速分配和释放内存空间。
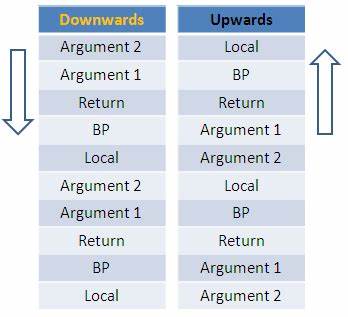
尤其是在x86等主流架构平台上,栈通常被设计为向内存地址较低方向增长。换句话说,每次函数调用时,栈指针会减小,分配新的栈帧。 然而,当我们深入到栈帧内部时,情况变得没有那么直观。栈帧是每个函数调用在栈上的内存区间,存放局部变量、返回地址和保存的寄存器状态。栈向下增长仅指出栈帧整体分配所遵循的地址方向,但局部变量在栈帧中的分布顺序则由编译器决定。 以C语言为例,假设有如下代码: int main() { int a, b, *p; p = &a; printf("%p == %p\n", &b, p + 1); return 0; } 这段简单程序的输出会显示变量b的地址与指针p向后偏移一个整数大小的地址相同。
乍看之下,许多程序员会疑惑,因为x86架构的栈是向下增长,理应变量b的地址比a的地址要小才对,为什么b的地址反而更大? 关键在于理解栈增长和变量布局是两个不同的概念。栈指针的移动方向反映的是栈帧的分配方向,但局部变量在栈帧内的排列方式完全依赖于编译器的策略。大多数编译器会将局部变量以地址递增的顺序排列,这样便于访问且更符合内存对齐要求。 换句话说,尽管整个栈帧是向低地址分配的,但局部变量从栈帧的底部依次向高地址排列。就像一个盒子(栈帧)放在桌子上,桌子往里缩,盒子也随之移向较低地址,但盒子内部的物品(局部变量)仍是按照从左到右依次摆放。 为什么编译器不反其道而行之,将局部变量按照栈增长方向反向排列呢?主要原因是编译器在生成代码时需要考虑访问效率、内存对齐、变量类型和可能的优化策略。
连续排列的变量能减少寻址复杂度,也有助于自动向量化和寄存器分配等优化。 此外,还需要指出的是,局部变量内存布局的细节是编译器的内部实现行为,不同编译器甚至相同编译器在不同优化级别下都可能有所不同。程序员不应该依赖变量在内存中相邻或排列顺序来做指针运算,因为这种行为是不安全且不可移植的。 在实际编程和调试过程中,对栈的理解能够帮助定位栈溢出、内存损坏以及函数调用相关的错误。但要谨记,局部变量地址的大小关系并不代表整个栈的增长方向。栈增长向下本质上是栈指针(SP)及栈顶的移动趋势,而局部变量的排列则是在分配好的内存区域中安排变量的顺序。
对于高级程序开发者和系统底层工程师来说,了解这一原理有助于更加深入地掌握内存布局,有效应对复杂的内存管理任务,例如栈帧回溯、函数调用链分析及安全漏洞挖掘。 总结来看,栈的增长方向和局部变量在栈帧内的排列是两个不同层面的设计。栈在x86平台上的确是向下增长,但编译器为了效率和优化,会将局部变量按从低地址到高地址的顺序排列。指针算术操作对局部变量间的安全性有限,仅适用于数组等连贯内存结构。 正确理解栈和局部变量的内存布局,有助于避免编程中的潜在陷阱和误解,从而编写出更加健壮、安全和高效的代码。这一知识点不仅是C/C++程序员的基础技能,也对学习底层语言和理解计算机架构有着重要意义。
掌握它,你将在编程和调试的道路上更加游刃有余。