在法律行业,信息的准确性与连贯性至关重要。法律文档通常内容庞杂,词句严谨且高度专业,涉及案例、法规、合同条款以及先例等复杂关系。传统的信息检索系统面临诸多挑战,尤其是在处理多文档、多实体之间关系时,往往难以捕捉细微的语义联系,导致法律信息检索效率低下,甚至存在信息遗漏的风险。近年来,随着人工智能特别是大语言模型(LLMs)的飞速发展,结合知识图谱的技术,正为法律信息管理带来全新变革,推动行业向智能化、精准化迈进。知识图谱作为一种结构化的数据表示方式,能够清晰地描绘实体间的多样关系,为复杂的法律文本提供逻辑架构支持,使得系统不仅能识别单个条款,更能理解条款之间、合同双方以及相关法律规定的内在联系。这为解决传统基于向量的检索手段无法深入推理和多跳查询的问题提供了有效途径。
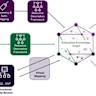
构建知识图谱的第一步是从非结构化文档中提取可用的信息。借助先进的解析工具如LlamaParse,可以高效地将PDF等格式的法律文档转化为可读的文本内容。之后,通过大语言模型进行合同类型分类,实现对不同法律文件的上下文理解。不同类型的合同包含不同的条款结构和法律要素,因此准确分类能显著提升后续信息抽取的针对性和准确性。分类完成后,利用专门设计的提取模型如LlamaExtract,基于预定义的结构化模式(Schema),从文本中抽取具名实体、关键条款、日期、地理信息及合同双方等详细信息。该过程不仅捕获显式内容,更能通过深度语言理解提炼复杂法律概念,如排他性条款、利润分成或知识产权归属等,为后续图谱构建提供丰富维度数据。
完成抽取后,将信息导入Neo4j等图数据库,构建涵盖合同、当事人及地点等多类型节点和它们之间关系的知识图谱。合同节点记录合同的核心细节和条款,当事人节点反映签约方信息,地点节点则关联具体的地理信息。通过建立多层次、多维度的关系网络,知识图谱实现了对法条内在逻辑和实体交互的可视化与高效查询。这种结构化表示使检索系统具备更加智能的推理能力,支持复杂的问题回答,例如查找涉及特定地域的所有相关合同,或者分析某个当事人在不同协议中的职责与权利变迁。与传统依赖简单相似度搜索的RAG(检索增强生成)系统相比,GraphRAG结合了知识图谱的强大结构优势,避免了信息碎片化,增强了上下文连贯性和多跳推理能力。法律领域的应用前景尤为显著。
考虑到法律文件的高度关联性及严苛准确性要求,知识图谱不仅提升了信息检索的精确度,也增强了对法律规则复杂互动的理解,从而降低合规风险,加快案件审理流程,提高律师和法律专业人员的工作效率。同期,智能抽取与图数据库技术的发展降低了手工整理法律资料的成本,促进了法律数字化转型和创新应用的落地。整个流程的自动化和智能化使得从文档解析、合同分类、信息抽取再到图谱构建成为一个高效而连贯的闭环,为法律工作者提供了强有力的工具支持,让法律数据变得更"活",能够主动服务于决策和分析需求。未来,随着知识图谱与生成式AI的进一步融合,法律智能系统将不仅限于信息检索功能,还将具备合约风险识别、自动合同审查、法律建议生成等能力。端到端的智能化流程有望彻底改变法律服务生态,推动行业实现更高效率与更优体验。综上所述,从法律文档向知识图谱的转变,不仅是技术层面的创新,更是法律信息管理思维的革新。
它将繁复、多元的法律文本转化为可操作、可推理的知识网络,极大地提升法律信息处理的正确性与便捷性。随着技术的日趋成熟,越来越多的法律机构和企业将采用知识图谱技术,打造全新的智能法律服务,推动法律行业迈向数字智能新时代。 。









