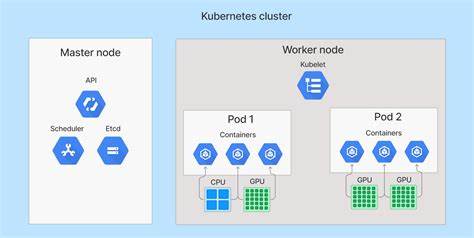
随着云计算和容器技术的迅猛发展,Kubernetes已成为现代应用程序部署和管理的核心平台。尽管Kubernetes提供了强大的编排能力,但如何高效、透明地实现Pods的状态保存与恢复,一直是业内关注的热点。而“Checkpoint Kubernetes Pods”(K8s Pods透明检查点)技术的出现,为解决这一难题带来了新的思路和突破。本文将全面探讨这一技术,结合CPU和GPU加速的应用场景,揭示其背后的原理、实践价值以及未来发展趋势。 Kubernetes Pods作为部署应用的基本单元,包含一个或多个容器。Pod内容器的状态管理对于保证服务的连续性和弹性至关重要。
传统的保存和恢复机制往往依赖外部存储或复杂的镜像重建流程,存在操作复杂、性能瓶颈和不够灵活等问题。透明检查点技术的核心理念是通过捕捉Pod运行时状态(包括内存、进程、网络连接等),实现快速而无缝的迁移、恢复或回滚操作。这样,开发人员和运维团队可以更轻松地应对故障恢复、负载均衡和动态扩缩容等场景。 现代工作负载特别是机器学习、图形处理和科学计算等领域大量依赖于GPU资源。如何在GPU加速下实现高效的Pod检查点成为技术难点。相比传统的CPU环境,GPU设备状态的复杂性和硬件依赖性要求检查点方案具备更深入的硬件感知能力和智能管理策略。
通过协同GPU驱动、容器运行时和Kubernetes调度器,透明检查点技术不仅支持纯CPU容器的状态保存,也能实现GPU加速Pod的高效迁移,最大限度地减少停机时间和资源浪费。 从技术实现角度来看,透明检查点一般依赖于Linux内核的CRIU(Checkpoint/Restore In Userspace)项目。CRIU能够冻结运行中的进程,导出其状态并在稍后恢复,支持进程间通信、文件描述符和网络套接字等关键属性。将CRIU融入到Kubernetes生态中,需要对Container Runtime Interface(CRI)进行扩展,同时兼顾容器安全、资源隔离和权限管理。对于GPU环境,则需集成显卡管理库和驱动读写接口,以确保存储的状态能够完整重现GPU上下文。 在实际应用中,透明检查点技术显著提升了Kubernetes集群的灵活性和鲁棒性。
通过无缝暂停和恢复Pod,支持在线升级、灾难恢复和灵活调度,降低了服务停机风险。例如,在大规模机器学习训练任务中,允许 checkpoint恢复使得计算作业可以跨节点迁移,加快了资源调度效率。 尽管优势明显,该技术目前仍面临一些挑战。包括多租户环境下的安全隔离、GPU驱动兼容性和检查点数据的存储管理等问题。社区和企业正在不断研发更完善的工具链,推动标准化接口,以及增强与云服务平台的集成,未来有望实现透明检查点技术的广泛普及和生态协同。 综上所述,通过透明检查点技术,Kubernetes Pods的状态管理迈入了新的阶段,无论是传统CPU计算,还是GPU加速领域,都能实现高效、灵活且安全的容器生命周期操作。
随着相关技术的成熟与生态的完善,这将为云原生应用的稳定性和可维护性提供坚实的技术保障,极大地推动云计算和容器技术的持续创新与发展。