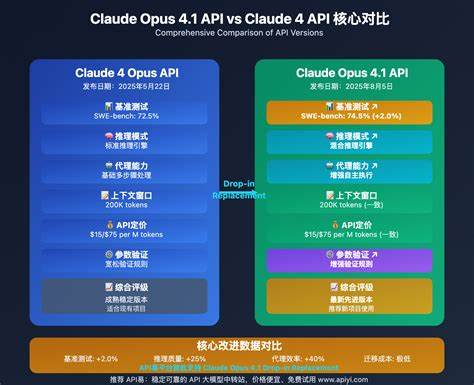
近年来,随着人工智能技术的飞速发展,大型语言模型(LLM)日益成为数字化服务和智能应用的核心动力。Anthropic公司推出的Claude系列模型因其优异的性能和创新的架构备受关注,尤其是Claude Opus 4.1和Opus 4版本,长期以来被视为业界高质量模型的代表。然而,2025年8月底发生的一起推理堆栈升级故障,导致这两个版本在约56.5小时内出现显著的质量下降,给用户体验带来了不小的冲击。本文将对这次事件进行详尽分析,探讨其根源、表现以及从中获得的启示。 Claude Opus 4.1与Opus 4备受推崇的原因在于其一致性和稳定的输出质量。Anthropic公司坚持在不更改模型权重的情况下保持版本号不变,从而避免用户因频繁更新模型而产生混淆。
此前,针对模型质量下降的投诉多数经证实为误解或其他因素所致。然而,本次情况则另有不同根由,从而引发了行业的高度关注。 具体情形发生于2025年8月25日17:30 UTC至8月28日02:00 UTC期间,持续时间约为56.5小时,Claude Opus 4.1遭遇推理堆栈升级错误而导致层层性能下滑。用户普遍反映AI表现出智能度明显降低、生成内容的语义连贯性下降,甚至出现了格式混乱和工具调用异常,尤其在Claude Code代码工具调用环节受到严重影响。这类问题不仅影响了普通的查询体验,也对依赖Claude进行代码辅助和复杂任务处理的用户群产生了现实影响。 所谓推理堆栈升级,通常是指对模型推理时所依赖的硬件、软件和算法进行升级优化,以提升效率和响应速度。
然而,一旦升级过程中存在缺陷或错误,可能导致模型调用流程的混乱,从而影响最终输出质量。此次事件据报道为一次"推理栈"故障,Anthropic迅速采取了回滚措施,恢复至升级前的稳定状态。此外,调查显示Claude Opus 4.0也受到同样的问题困扰,相关团队正积极进行相应的回滚处理。 当机器学习模型尤其是大型预训练语言模型部署在生产环境中时,保持高可用性和稳定性是首要任务。虽然模型本身的权重不变,但推理环境任何细微变化都可能对输出质量造成影响。这次事件揭示了软件堆栈层面风险管理的重要性,提示企业在升级和维护复杂AI系统时必须更加谨慎,全面测试每一环节的兼容性。
另一方面,事件也折射出用户对模型质量的高度敏感度。过去许多关于"模型质量下降"的投诉往往是因用户环境、请求方式、网络延迟等因素引起。此番真正由技术升级错误导致的普遍质量回落,在行业内形成了明显对比,促使厂商重新审视升级策略以保证改动透明且可控。 此外,Claude Opus 4系列作为Anthropic面向市场的主要AI产品,其稳定性直接影响企业品牌形象和客户信任度。Anthropic在事件发生后及时沟通公告,说明故障原因并承诺修复进度,赢得不少用户理解。这种危机管理方式值得业界借鉴,强调开放透明和用户第一的重要原则。
此次质量波动还对人工智能技术评估提出了新的挑战。随着模型规模和复杂性不断增加,传统的基准测试不再完全满足实际应用需求。评估人员需考虑升级带来的上下游影响,设计更全面的质量检测体系。此外,实时监控和快速故障响应机制成为行业不可或缺的保障工具。未来AI模型的发布和维护将进入一个更精细化、系统化的阶段。 从技术视角看,推理堆栈的升级失败可能涉及多方面因素,包括软硬件兼容性、缓存机制、并发请求处理、负载均衡策略等。
对这些底层环节的风险管理和回滚策略规划需要投入大量资源确保万无一失。Anthropic此次虽然经历了质量下降的尴尬,但也积累了宝贵的运维经验,为今后面对更大规模的AI产品推出奠定基础。 面向未来,Claude系列及整个大型语言模型行业可从此次事件中吸取教训。首先是升级流程需引入多阶段测试、灰度发布及用户体验数据实时反馈,减少生产环境突发异常风险。其次,加强用户沟通和反馈机制,持续听取第一线意见快速调整。最后,加大对推理堆栈底层架构的创新投入,提升稳定性和弹性。
只有如此,才能保障人工智能服务持续为各类应用提供强有力支持,促进行业健康发展。 总的来说,Claude Opus 4.1与Opus 4因推理堆栈升级失误而短暂出现的模型质量下降事件,尽管对用户体验带来冲击,但也成为人工智能模型运维与管理领域极富价值的案例。它提醒我们,先进技术背后的稳定运行是用户信任的基石,而风险管理和快速响应是保障持续创新的关键环节。Anthropic的积极应对和透明态度为业界树立了良好典范。未来,随着技术迭代加速,类似事件的预防与高效处理能力将成为各大AI厂商竞争力的重要组成部分。用户与开发者共同推动AI生态圈更趋成熟,期待Claude及其他领先模型能够在稳定性与智能化方面实现更大突破,带来更加优质和可靠的智能体验。
。