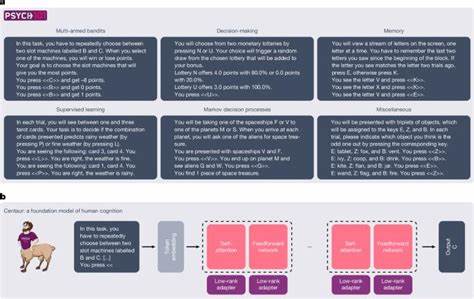
在人类认知科学的研究领域,长期以来科学家们都在追求一个终极目标——建立一个统一的认知理论。试图通过一个模型来解释和预测人类在各种环境和任务中的复杂行为。然而,传统的认知模型通常都是针对具体任务或领域而设计,缺乏跨领域的泛化能力,使得对认知整体的理解受到限制。随着人工智能技术的迅猛发展,尤其是大语言模型(LLM)的兴起,一个全新的契机出现了。最近,一个被称为“Centaur”的基础模型的问世,为人类认知研究打开了崭新的大门。它不仅能够预测人在广泛心理学实验中做出的具体选择,还能够在未见过的任务和环境中具备强大的泛化能力。
Centaur基于对超过六万名参与者完成的160个不同实验中超过一千万次行为选择的海量数据集进行细致的训练,从而学习到人类行为背后的深层认知机制。 这种模型是如何构建的?研究者们选用了Meta AI发布的前沿大语言模型Llama 3.1 70B作为基础,通过一种名为量化低秩适配法(QLoRA)的参数高效微调技术,在庞大的“Psych-101”数据集上进行训练。该数据集涵盖从多臂老虎机任务、决策制定、记忆、监督学习到马尔可夫决策过程等多种认知任务,数据全部以自然语言形式表达,便于模型理解和处理。通过仅微调模型中的少量附加参数,Centaur成功地保留了原模型的广泛知识储备,并且显著提升了其对人类具体行为的拟合能力。 Centaur在实际测试中表现令人瞩目。它不仅能准确预测训练外参与者的行为,还能适应实验中的封面故事变化、任务结构调整甚至全新的认知领域。
比如在经典的“两步任务”中,Centaur成功捕捉到参与者在模型自由与模型基于学习上的差异,这种细腻的行为分布对传统认知模型而言颇具挑战。此外,当面对非人类决策,模型的准确率会大幅下降,表明其聚焦于人类认知的独特规律而非一般统计规律。 除对行为数据的卓越拟合,Centaur在神经层面的对齐表现同样出色。研究人员利用功能性磁共振成像(fMRI)数据,将模型内部表示与人类大脑活动进行比对,发现经过专门微调的Centaur在多个脑区的活动预测上优于未微调的大语言模型。这种行为和神经数据的双重对齐,进一步证实了其作为人类认知强有力的计算表征基础。 不可忽视的是,Centaur的出现也为认知科学的研究方式带来了深远影响。
借助这类大型基础模型,研究者能够跨实验、跨任务地整合海量数据,从而构建出具备高度泛化性的认知解释框架。此外,模型还能辅助开发新的认知策略,启示科学家重新审视并创新理论体系。在一个多属性决策的案例中,Centaur帮助发现人类结合多种启发式策略作出决策的潜规律,优化了既有的解释模型。 未来,Psych-101数据集和Centaur模型还有巨大的扩展潜力。当前数据主要涵盖学习和决策领域,后续可以引入更多认知分支,如语言心理学、社会心理学以及经济游戏等,全面反映人类思维的多维面貌。对个体差异、发展心理学或计算精神病学的整合,也将为个性化认知建模铺路。
通过不断完善和多模态数据融合,最终有望实现真正意义上的统一认知计算模型。 正如早期认知科学家担忧的,构建统一模型往往面临传统理论流派的抵触。然而Centaur凭借其在16个经典认知任务上的持续领先表现,证明了基于大规模数据驱动的认知建模道路的可行性。它不仅是一种预测工具,更是一个开拓认知理论的新平台。未来的研究应关注将数据驱动的基础模型转化为具有解释力和理论价值的统一认知框架,推动跨学科合作,加速神经科学、认知心理学与人工智能的深度融合。 总的来说,Centaur的诞生象征着人类认知研究进入了一个新时代。
它完美结合了先进的大语言模型技术与心理学海量实验数据,不仅在准确捕捉行为细节上实现了突破,更在理论探索和科学发现上开启了诸多可能。随着技术进步和数据规模的扩大,这类基础模型将在认知科学、神经科学以至人工智能领域发挥愈加重要的作用。理解人类认知的统一奥秘,正迈向前所未有的科学征程。









