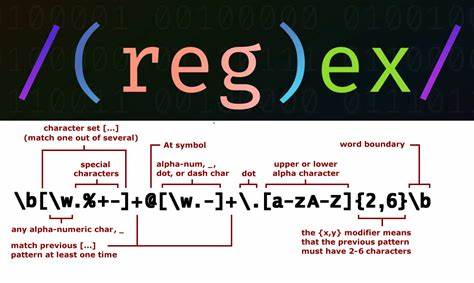
随着人工智能技术的迅猛发展,大型语言模型(LLM)已经成为自然语言处理领域的核心工具。它们能够理解和生成自然语言,应用于机器翻译、文本生成、智能问答等多种场景。然而,虽然这些模型在实际应用中表现优异,但它们内部复杂的机制和高维词汇空间却鲜为人知。许多人对模型如何组织、表示词汇产生好奇。将LLM的词汇空间进行可视化,成为理解模型内部运作的一个有效途径,让复杂的数据以更直观的方式呈现,便于研究人员和开发者深入分析。大型语言模型的训练过程建立在海量语料基础之上,首先需要对文本进行分词,即将文本拆分成若干基本单位 - - 词元(Token)。
每个词元都用一个高维稠密向量表示,称为嵌入(Embedding)。这些向量是模型通过训练自动学习得到的,包含丰富的语义信息和词汇间关系。以LLaMA 3模型为例,其词汇量约为12.8万个,词元嵌入的维度则高达4096维,这意味着模型在4096维空间内管理着超过十万点的词元分布。如此庞大且高维的数据难以直观理解,如何将这些信息转化为人类能够感知的形式,成了可视化研究的关键。为了有效可视化并保持语义结构,研究人员通常采用降维技术,诸如主成分分析(PCA)将高维向量降到三维空间,方便通过三维散点图进行展示。虽然降维不可避免地会丢失部分细节,但整体语义趋势和相似词的聚类特性依然清晰可见。
可视化研究通常会从实际文本中筛选出出现的词元,避免了展示整个庞大词汇表,既减少了计算负担,也提升了图形的可分析度。例如,利用维基百科的文本片段,提取实际出现的词元进行分析。通过对文本分词并统计词频,可以在三维空间中按词频分层或着色,观察高频词与低频词的分布差异。此过程不仅呈现了词元的语义聚类,也显示了词频等词汇属性的空间映射关系。在实现过程中,Hugging Face的Transformers库成为关键工具,方便加载LLaMA等预训练模型及其分词器。模型的词嵌入权重可直接提取,通过PCA降维后结合Plotly等交互式绘图库,构建动态三维视觉图。
用户能够通过旋转、缩放和悬浮提示,交互式探索词元空间,直观感受词汇相关性背后的潜在逻辑。例如,在可视化结果中,地名、专有名词往往聚集在特定区域,经济术语或动词类词汇则呈现另一类空间分布。这种现象反映了模型根据上下文和语义共现信息自动形成的词汇组织模式。进行词汇嵌入可视化还可以对特定文本进行定制化分析,比如对《神曲》这样经典作品的词汇空间可视化,不仅帮助理解模型在古文语境下的词汇表达,还能辅助文学研究与语言学习。尽管完整词汇表的可视化具有较高的计算成本和存储需求,但对于需求深入理解词汇全貌的研究而言,仍是不可或缺的探索方向。除主成分分析外,研究者也尝试其他降维方法如t-SNE和UMAP,以期捕捉更细腻的局部结构和非线性映射效果,这些技术在展示相似词和语义流变方面表现出色。
通过对词汇嵌入空间的细致分析,不仅可以增强对模型训练机制的理解,还能发现潜在词汇偏差和语义盲区,进一步指导模型的优化和设计。语义嵌入的可视化还启发了诸多应用创新,包括领域自适应模型训练、词汇扩展与清洗,乃至于更有效的文本生成控制与个性化推荐。探索高维词汇空间的奥秘,不仅是人工智能技术进步的需求,更有助于推动语言理解与交互的未来。通过科学合理的可视化方法,将抽象的数学向量变为直观的视觉形象,为学术界和工业界提供了宝贵的洞察视角。随着模型规模的不断扩大与技术的不断迭代,未来词汇嵌入空间的可视化将更加精准、丰富,助力人们深入挖掘自然语言本质,创造更多智能化应用场景。总之,词汇嵌入的可视化不仅满足了对模型内部结构的好奇心,更是理解语言模型深层语义关联的重要手段,是揭示复杂自然语言机制的一扇重要窗口。
。