随着科技的不断进步,现代计算机的性能已经不再仅依赖于单核处理速度的提升,而是通过大规模并行计算能力的释放,实现了性能的飞跃。无论是台式机、笔记本电脑,还是服务器与超级计算机,几乎所有设备都采用了多核CPU和强大的GPU来满足日益增长的计算需求。在这样的背景下,深入理解并行计算并掌握相关编程技术,成为提升软件性能的关键所在。现代计算机CPU内隐藏着大量的并行资源。一个普通的四核处理器每个核内包含多个执行单元,这些执行单元可以同时处理多条指令。更重要的是,许多处理单元支持宽向量操作(一条指令处理多个数据),并且使用流水线技术实现指令的重叠执行,让处理器在任何时刻都处于高效运转状态。
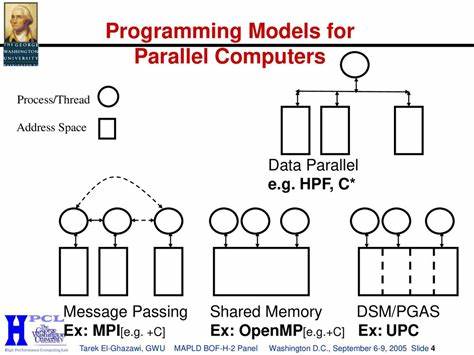
尽管硬件具备如此强大的潜力,如果程序员对并行性的利用不足,就会导致计算资源的极大浪费。在一些简单的顺序程序中,可能仅仅发挥了不超过2%的单核性能,更不用说利用多核的优势了。显然,想要在现代硬件上获得令人满意的性能,仅仅依靠传统的编写技巧是远远不够的。要实现性能的大幅提升,开发者需要理解多线程编程的基础,掌握如何有效拆分任务并协调线程工作。同时,还要准确把握底层硬件的执行机制,合理安排指令顺序、数据访问模式和缓存利用,从而避免性能瓶颈。更进一步,开发者还能通过向量化优化(SIMD指令集)实现单核上的并行加速,发挥处理器内每个执行单元的最大潜力。
相比CPU,现代GPU则更像是专门为并行计算设计的“超级工厂”。其拥有成百上千的计算核心,可以同时执行海量线程,对数据并行任务有着显著优势。虽然GPU最初是为图形渲染服务,但如今已经演变为通用计算平台,广泛应用于科学计算、大数据分析、机器学习等领域。然而,GPU的强大能力并不能自动被传统的C++程序利用。编程GPU需要开发者使用诸如CUDA、OpenCL等专门的编程框架,明确管理设备与主机之间的内存传输,以及合理组织网格和线程块结构,最大化硬件吞吐量。尽管听起来复杂,这些工具和方法经过高度抽象和封装,使得主流开发者也能以较低门槛入门GPU编程,享受显著的性能提升。
深入学习并行计算不仅需要掌握编程技术,更要理解性能工程背后的硬件原理。通过分析汇编代码、观察CPU流水线行为,开发者能够预测代码性能表现,找到瓶颈所在,并针对性地优化程序。这样的技能不仅提升代码效率,更为面对未来硬件架构变化打下坚实基础。值得强调的是,编写高效并行程序不仅是一项技术挑战,也是现代软件开发的基本要求。随着软件应用对实时响应、大数据处理能力的要求不断提升,无论是互联网企业、科研单位还是游戏开发者,都必须将并行编程能力纳入核心竞争力。幸运的是,当前丰富的教学资源和在线课程使得学习并行计算变得更加轻松和便捷。
Aalto大学提供的公开课程“Programming Parallel Computers”就涵盖了从基础概念到进阶优化,帮助学习者成为能够巧妙利用现代硬件性能的开发者。总的来说,现代计算机的强大并行能力是硬件发展带来的巨大机遇,程序员只有主动拥抱并行编程技术,才能将这一潜力转化为实际的性能提升和效率改进。理解并行计算、掌握多线程与GPU编程、具备基本的性能调优思维,将是未来计算领域的核心能力。无论是科研、工业应用,还是日常软件开发,只有紧跟这一潮流才能在激烈的技术竞争中立于不败之地。