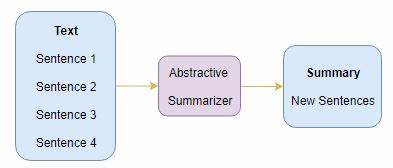
随着信息量的爆炸式增长,自动文本摘要技术日益重要,特别是抽象文本摘要(Abstractive Text Summarisation)因其能够生成更加精炼且语义丰富的摘要,成为自然语言处理领域研究的热点。抽象摘要通过理解原文含义并重新组织语言,生成高质量的简短文本,区别于传统的提取式摘要,其难度和智能含量更高。当前,抽象摘要技术不断发展,新一代模型以深度学习和预训练变换器架构为基础,极大提升了摘要的流畅度和准确性。本文将深入剖析当前最先进的抽象文本摘要模型,分析其架构、评测标准、以及在本地部署的可行性,帮助读者全面掌握前沿进展。首先,理解当前抽象摘要模型的技术背景极为重要。近年来,基于Transformer架构的预训练语言模型引领了自然语言处理的新浪潮。
诸如BERT、GPT系列、T5和BART等模型,因其在大规模语料上的预训练,具备强大的语言理解和生成能力,成为抽象摘要的技术基石。特别是T5(Text-to-Text Transfer Transformer)和BART(Bidirectional and Auto-Regressive Transformers)模型,将文本摘要视为序列转换任务,显著优化了生成效果。BART结合了编码器和解码器的优势,经过对大量文本的无监督预训练,能够更好地捕捉语言多样性与上下文关联,是目前许多抽象摘要系统的首选。而T5则将所有文本处理任务统一为文本到文本的转换框架,展现了极强的泛化能力和灵活性。除了上述通用模型,最近也涌现出专门为摘要任务设计的变体和轻量化版本,旨在提高推理速度和减少资源消耗,使得本地运行变得可能和便捷。评估标准对于衡量摘要质量至关重要。
当前主流的抽象摘要评测指标包括ROUGE、BERTScore以及基于人工智能的G-Eval、SummEval、SUPERT等多维度评测体系。ROUGE指标通过计算摘要中词汇的重叠度衡量性能,长期以来被视为摘要质量的基石。BERTScore则采用预训练语言模型匹配词语的语义相似度,更精准反映文本含义。近年出现的G-Eval、SummEval和SUPERT等评估工具,整合了人工评分与自动化评价,提供更全面的摘要质量判断,特别在评估信息完整性、流畅度和事实准确性方面具有优势。尽管如此,最新模型的公开评测数据相对有限,面对快速变化的研究格局,社区内呼吁定期更新权威评测结果以指导实际应用选择。针对用户希望在本地部署抽象摘要模型的需求,近年来硬件性能提升和模型结构优化推动了本地运行的可行性。
大规模预训练模型通常参数庞大,运行时需要高性能GPU支持,这对普通用户提出了挑战。然而,量子蒸馏、模型剪枝等技术的应用,使得轻量级模型在保留核心性能的同时,显著降低了计算资源需求。诸如DistilBART、TinyT5等轻量化变体提供了在中端硬件上进行文本摘要处理的解决方案。访问开源社区,用户还能下载微调好的模型权重,实现针对特定领域文本的高效摘要。使用本地模型的最大优势在于数据隐私和处理速度,尤其适合处理敏感信息的企业和个人。除此之外,终端优化方案如ONNX加速、量化模型和混合精度计算等技术手段也正在普及,使得模型部署更加高效。
在选择合适的抽象摘要模型时,用户应结合文本特点、应用场景和硬件条件合理选择。对于需要高度准确且风格多样的摘要任务,基于BART或T5的预训练大模型仍是首选。对资源有限且需要快速生成摘要的场景,轻量版本和定制化微调模型体现出更大优势。此外,不同领域文本(如新闻、科技文献、法律文件等)的语言和结构差异也对模型的微调提出了要求。未来,随着多模态学习、知识增强和因果推理技术的引入,抽象摘要模型有望在准确性和信息增量方面实现更大突破。与此同时,社区合作和开源项目的发展将持续推动评测方法和标准的完善,促进模型的公平比较与真实应用。
综上所述,当前抽象文本摘要领域的最先进模型主要依赖于基于Transformer结构的预训练语言模型,特别是BART和T5在生成质量方面表现突出。评测工具正趋向多维度综合评价,提升了对摘要效果的理解深度。轻量化模型和优化技术大大增强了本地部署的可行性,满足不同用户的实际需求。随着技术的快速演进和应用场景的不断丰富,抽象摘要技术必将成为信息处理和知识获取的重要助手,助力人们应对日益复杂的信息环境。 。