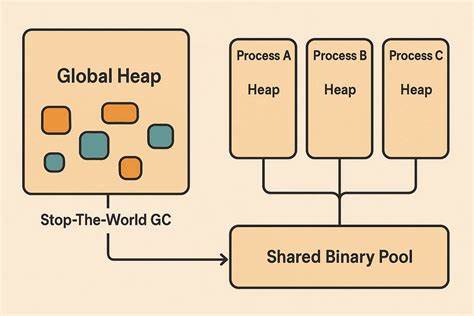
随着人工智能技术的飞速发展,模型的规模与复杂度不断提升,如何高效地调度计算资源成为业界关注的核心难题。近期,领先的模型运行平台Ollama发布了其全新模型调度系统,带来了革命性改进,尤其是在内存管理和多GPU性能优化方面展现出显著优势。本文将深入解读Ollama新模型调度系统的技术创新和实际应用价值,帮助读者全面了解其在提升模型运行效率、稳定性及资源利用上的突出表现。 Ollama新调度系统的核心亮点在于摒弃了传统的内存估算方式,转而采用精准测量模型实际所需内存的策略。以往版本仅凭估算值进行内存分配,难免导致分配不足或过度,进而频繁发生因内存溢出导致的崩溃。如今,Ollama引入全新的内存测量引擎,能够准确评估模型运行时所需的内存规模,显著降低内存分配误差。
这一做法不仅减少了运行过程中的崩溃事件,更保障了模型执行的稳定性与连续性。 与此同时,新引擎在多GPU调度策略上实现了重大突破。在此前的多GPU环境中,设备间资源分配往往不均衡,或者由于硬件配置差异造成性能瓶颈。新的调度系统通过智能负载均衡算法,能根据每块GPU的性能与内存容量动态分配计算任务,极大地提升了多GPU协同工作效率。不仅如此,即使面对混合型号或规格不一的GPU设备,新系统仍能高效调度,充分挖掘硬件潜力,为大规模模型推理与训练提供坚实保障。 除了内存管理和多GPU调度,Ollama的新系统在GPU利用率提升方面也表现卓越。
通过精细的资源分配,新引擎能够更加合理地利用显存空间,释放更多计算资源用于加速Token的生成和处理。在实际测试中,采用NVIDIA GeForce RTX 4090单卡环境运行长上下文模型gemma3:12b时,模型的Token生成速度从旧版的约52 tokens每秒提升至85 tokens每秒,显存使用也由19.9GiB提升到21.4GiB,更加充分地加载模型全部层数,提高计算效率和响应速度。 多卡环境下的表现更为惊艳。以两块RTX 4090 GPU运行支持图像输入的mistral-small3.2模型为例,新调度系统使提示评估速度从原先的127 tokens每秒飙升至1380 tokens每秒,Token生成速度也明显提高。显存使用优化允许全部模型层加载到GPU,包括视觉模型模块,有效提升了给定任务的整体性能体验。 这项技术升级对AI开发者和企业应用场景意义非凡。
首先,降低了因内存溢出等资源错误导致的任务失败概率,让模型推理与训练更加稳定高效。其次,多GPU的智能调度使得扩展大规模模型成为可能,不再受限于单卡显存瓶颈,进而支持更长上下文、更复杂的多模态任务需求。最后,通过提升GPU利用率和速度,用户能够在相同硬件条件下完成更多计算任务,降低硬件投资成本,提高ROI。 目前,Ollama已在旗下多个主流模型中全面启用了新引擎,包括热门的大型语言模型如gpt-oss、 llama系列(部分版本正在逐步迁移中)、gemma3系列、qwen3及mistral-small3.2等多种类型,并计划将此优化拓展至更多迭代版本及嵌入式模型。未来随着更多模型适配新引擎,整个生态系统的性能与稳定性将持续提升,为人工智能算力领域注入强劲动力。 从行业角度看,Ollama此举响应了AI计算资源需求日益增长的趋势。
在机器学习模型不断加深、推理任务更加复杂的当下,内存管理和计算调度成为制约效率的关键因素。精细且智能的调度方案正逐渐成为技术突破的焦点,有望推动AI算力硬件与软件协同优化达到新高度,满足更大规模、多样化、多模态的计算需求。 展望未来,Ollama的新模型调度系统体现了AI运行平台在算力利用上的进化方向。精准内存测量结合灵活智能的多GPU调度,不仅带来性能提升,还为用户提供了更可靠、更高效的模型执行环境。同时,该技术也为其他AI平台和硬件厂商树立了标杆,促进整个行业技术进步。随着持续研发投入和广泛应用推广,更多创新的硬件资源管理方案将不断涌现,为人工智能技术普及和商业落地提供坚实支撑。
总结来看,Ollama全新模型调度系统通过创新的内存管理和多GPU调度策略,有效解决了传统模型运行中存在的内存溢出、资源浪费及多卡协同低效等难题,显著提升模型运行速度与稳定性。对于AI开发者、数据科学家以及各类企业用户而言,这项升级极大地优化了算力资源的利用效率,降低了运行风险,显著提升了模型推理与训练的整体体验和成果。随着技术迭代的持续推动,Ollama在模型调度领域的领先地位必将稳固,并引领AI算力管理进入一个全新的发展阶段。 。