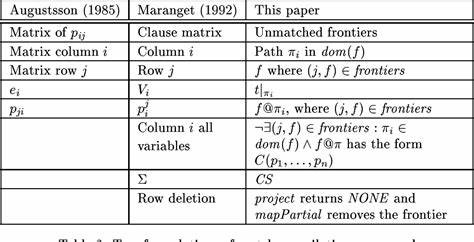
在现代静态类型的函数式编程语言中,模式匹配作为定义函数的核心机制,具备极高的重要性。模式匹配允许程序员通过简洁优雅的方式对复杂数据结构进行拆解和条件分支,是诸多高级语言设计的基石。然而,模式匹配最初的定义仅仅是顺序地将输入值与多个模式逐个比较,其直观实现往往无法满足性能需求。为了提升执行效率,现代编译器普遍采用自动机(automata)将多个匹配条件高效整合,通过决策树等结构,实现对输入值的批量、智能检测。决策树结构显著减少了匹配过程中的冗余计算,从而提升程序执行效率。但构造决策树的代价并不容忽视,尤其是其大小和形态直接决定了匹配的性能表现。
理论上,生成最优的决策树需要指数级别的编译时间,这在实际应用中几乎不可行。基于此,编译器设计者和语言研究者提出了各种启发式方法,以在合理的时间复杂度内产生近似最优的决策树。尽管大量启发式策略被研制和采纳,但其实际影响有多大,何时启发式方法才真正显得关键,依然是一个值得深入研究的问题。近期,Kevin Scott与Norman Ramsey联合发表的研究针对这一问题展开了实验评估,基于著名的Standard ML of New Jersey(SML/NJ)编译器,分析了不同启发式策略在实际程序编译中的表现差异。研究表明,在大多数常见的基准程序中,使用何种启发式几乎不会影响生成的决策树大小,所有策略产出的树结构几乎一致,性能差异有限。这意味着,对于日常软件开发中的典型代码,选择启发式方法并不是编译优化的决定性因素。
相比之下,仅少数程序的决策树大小会因启发式算法不同而有所变化,但这种变化通常也不会超过几个百分点。这样的数据结果表明,对于常规开发场景,过度追求启发式算法的完美可能收益有限,编译器设计应更多关注通用性能和可维护性。然而,对于专门的、机器自动生成的复杂程序,启发式算法的重要性则显著提升。在这些场景下,错误的启发式策略可能导致决策树大小暴增,性能下降高达数倍,甚至十几倍。显然,在高性能计算、自动代码生成以及特定领域编译时,合理选择启发式方法对最终编译结果有着至关重要的影响。深入理解这些启发式算法的内部运作机制与选择条件,对于优化编译器框架、提升程序运行效率尤为关键。
启发式方法本质上是以经验规则指导决策树构造过程,力求达到折中效果。它们根据模式结构及匹配路径的预期代价,试图选出既不至于暴涨规模又能保持匹配效率的树形架构。编译器通过一系列启发准则挑选分支模式与处理顺序,避免在某些极端模式列表上进行不必要的展开。与此同时,编译环境及程序设计风格的变化也会影响启发式的表现。例如,在拥有大量嵌套模式或复杂条件组合的匹配体系中,启发式方法可能发挥更大价值;而在较为直接和简单的匹配条件下,其影响则通常被弱化。此外,模式匹配的启发式编译直观地反映了计算理论与工程实践之间的平衡。
期望理论最优不切实际,而经验规则则能带来稳定与高效。理解这一点,不仅帮助编译器开发者设计更合理的模式匹配生成策略,也为程序员在代码设计时提供参考,避免构造导致启发式失效的极端匹配结构。总结来看,模式匹配编译启发式算法的价值体现为两个层面。在日常应用中,它们确保编译过程高效且低开销,维持程序整体的良好运行性能。在机器生成代码及复杂系统中,选择合适的启发式策略则是提升性能的关键途径。对启发式算法的深入研究和实验验证不断推动着函数式编程语言编译技术的发展,为语言实现和软件性能优化提供了坚实基础。
因此,无论是编译器研究领域的专家,还是希望提升程序性能的开发者,均应高度重视启发式策略在模式匹配中的作用及其选择时机。了解何时、为何启发式算法对决策树产生实质影响,是设计高效、健壮编译系统的必备知识。未来,随着编程语言日益复杂和应用场景多样化,启发式匹配编译技术必将继续演进,结合机器学习等新兴方法,提供更加智能和动态的优化方案。持续关注该领域的最新进展,将有助于更好地利用启发式算法,解锁函数式编程语言的更大潜能,推动软件行业迈向更高效的未来。