Apache Parquet作为一种广泛应用的列式存储格式,因其高效的压缩和查询性能备受数据工程师和分析师的青睐。然而,常见的误解是Parquet仅支持基础的Min/Max统计信息和布隆过滤器,若想实现更复杂的索引功能,必须改变文件格式或采用其他新格式。事实并非如此,Parquet文件的设计灵活,利用文件尾的元数据和基于偏移量的访问机制,完全可以嵌入用户自定义的索引结构,既不破坏文件兼容性,也无需额外文件系统支持。想象一个场景,在成千上万个Parquet文件中,数据包含了一个Nation字段,涵盖几十个独立值。仅靠原生的Min/Max统计因词典顺序跨度过大,无法有效进行文件裁剪和跳过。传统的布隆过滤器虽然有用,但不总能满足所有需求。
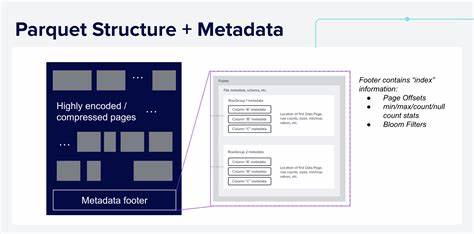
如果我们在文件末尾附近存储该字段的所有不同取值列表,查询时读取这份“小巧”的索引信息,从而快速判断是否包含特定国家的数据,便能大幅提升文件级别的跳过效率。更重要的是,这种用户定义的索引不会影响标准Parquet读写工具的正常工作。本文将带你深入了解Parquet文件的结构及它的标准索引组成,解析如何利用文件本身的灵活特性嵌入自定义索引,并以Apache DataFusion为例,展示如何读写和使用自定义索引进行查询优化。Parquet文件内部逻辑划分为多个Row Group,每个Row Group包含多个列数据块,再细分为数据页。文件底部存储着通过Thrift序列化编码的元数据信息,涵盖文件结构、模式、数据位置等。标准的Parquet索引通常包含每个数据块的Min/Max/空值统计信息,访问数据页的页索引,以及用于判断某值是否存在的布隆过滤器。
这些索引大多存储于文件体内部偏移位置,并在元数据中标注位置,提升读写效率。更高版本的库会自动创建并控制这些索引,用户也能通过相关配置接口定制索引生成。用户自定义索引嵌入的关键原理在于,Parquet格式允许文件内存在不被识别的字节片段,而且其元数据支持任意键值对。这意味着,我们可以将经过序列化的自定义索引以二进制形式写入文件体的任意位置(通常附加在数据段之后,偏移量记录于元数据),使索引与数据紧密绑定。这种设计避免了额外同步外部索引文件的复杂性,同时确保了向后兼容性和灵活的索引层级,包括文件级、Row Group级、数据页级甚至逐行索引。具体应用非常广泛,例如在文件或数据页层面存储字段的唯一值集合,实现快速过滤;利用HyperLogLog结构估算基数,改善统计信息不足的问题;或维护预计算总和、直方图等辅助信息,加速查询执行。
以最直观的例子——基于字段的唯一值索引为例,许多数据库和引擎已将其验证为高效的数据跳过手段,如ClickHouse的“set”跳过索引和InfluxDB中的唯一值缓存。在未排序字段场景下,该索引比传统的Min/Max裁剪更精确,因为它完全记录了该字段实际存在的所有值,使得诸如筛选“Category='foo'”时能精准排除不相关文件,避免误读结构性排序带来的漏判问题。构建唯一值索引的过程较为简单,通常将目标列的所有不同值收集后使用某种格式序列化,例如使用UTF-8编码的换行分隔字符串,并加上特定的魔术字节作为文件头,记录索引字节的偏移量和长度,并通过Parquet元数据写入相应的键值对,例如"distinct_index_offset"表示索引起始位置。在读取时,Parquet文件解析器首先读取元数据,获取该偏移量,再按格式反序列化唯一值集合,供查询使用。在Apache DataFusion中,为实现基于该自定义索引的文件跳过,会扩展其TableProvider接口,通过解析Parquet文件底部的自定义元数据和索引字节,预先加载每个文件对应唯一值集合。在执行过滤时,将SQL中的等值谓词与对应索引内容对比,快速剔除不包含目标值的文件,仅扫描必要数据。
这样既提升了查询效率,也减少了I/O开销。值得一提的是,嵌入的索引不会破坏与其他工具的兼容性。诸如DuckDB、Spark等流行系统未识别的自定义字节和额外元数据都会被忽略,确保传统工作流不受影响。用户可以借此技术在保持标准Parquet流畅适用的同时,针对特定业务场景定制高效的索引方案。技术社区与开源项目纷纷关注此方向,并在不断优化相关实现。虽然传统上外部索引方案因维护额外文件和同步风险而备受诟病,但Parquet自带的扩展能力为解决这些痛点提供了极佳契机。
未来,随着数据量与复杂场景的日益增长,嵌入式用户自定义索引将成为提升数据处理系统性能的重要利器。总之,在Parquet文件中嵌入用户自定义索引是通过利用其灵活的文件结构和元数据机制实现的有效方式。用户可以根据业务需求,将不同类型的索引序列化成二进制数据写入文件,元数据记录其位置,支持在查询时加载并应用,极大提升过滤和裁剪能力。该方案无需更改Parquet规范,兼容主流查询引擎,简化运维复杂度。随着Apache DataFusion等工具链的优化推广,未来基于嵌入式自定义索引的高性能分析将更为普及。系统设计者和开发者可利用此技术扩展Parquet应用边界,打造极致高效的分析平台。
。