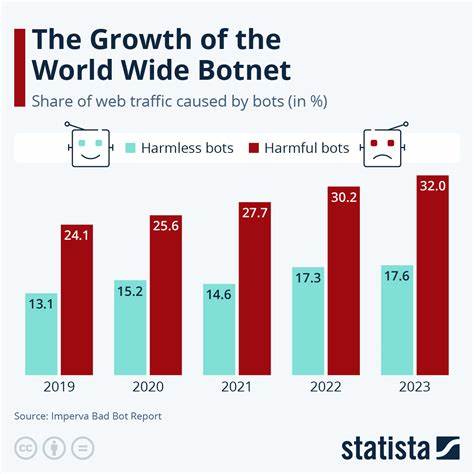
近年来,随着人工智能技术的突破与应用普及,人工智能工具,特别是以ChatGPT为代表的对话式大语言模型不断改变着人们获取信息的方式。传统依赖搜索引擎的用户习惯正在发生显著转变,越来越多的人选择通过AI助手直接获得答案,从而减少了对传统网页浏览的依赖。然而,这一变革也催生出了另一个鲜为关注但极具影响力的现象——大量流量来自执行网络抓取任务的AI机器人。根据美国新闻媒体报道和新兴科技公司的数据监测,2025年第一季度,来自AI抓取机器人的网站流量增长了近五成,远超普通用户访问和传统搜索引擎机器人。网络抓取AI机器人作为高度智能的数据采集载体,能够快速且大规模地爬取网络内容,用于训练、推理甚至代替人类完成复杂任务的背后支撑。然而,这一现象给内容发布者和网站运营者带来诸多难以解决的问题,最核心的困境是难以从这部分流量中实现内容变现。
传统的网页流量变现主要依靠广告曝光、付费订阅和内容电商等模式推动流量价值转化。可AI抓取流量往往不会像真实用户那样停留、点击广告或购买产品,甚至有不少情况下,AI机器人抓取内容后会将信息整合并以摘要、重写的形式呈现在第三方平台,进一步削弱了原始内容页面的访问价值和广告效应。由此导致内容创作者的收益受到直接侵蚀,并形成无法持续的商业生态。此外,现行网络抓取管理机制难以应对AI机器人带来的挑战。许多网站通过robots.txt文件、IP封锁和验证码等技术手段阻止爬虫访问,但AI抓取机器人往往采用更加隐蔽、灵活的方式绕过限制,例如伪装成合法用户代理、使用代理池或分布式抓取等。这不仅加重了网站的服务器负载和带宽成本,还对网站安全造成潜在风险。
与此同时,AI技术的发展使得数据抓取变得更加智能化和自动化。部分AI伴随多模态能力和任务代理功能,能够主动发起多轮请求并完成从信息查询到订单下达的一系列任务,展现出比传统爬虫更复杂、更多元的访问行为。这进一步加剧了抓取行为的隐蔽性和复杂性,令内容管理者更加疲于应对。内容提供方与AI企业之间在内容使用和版权归属方面的冲突日益升温。AI公司倾向于将网络公开信息视作“公平使用”的素材库,拒绝为内容抓取付费或授权。而内容创作者和媒体机构则强调,AI机器人直接复制和再利用内容侵犯了原创权益,要求AI企业建立合理的内容授权和收益分配机制。
此类矛盾的调和面临法律法规、技术标准和产业链多重考验,目前尚未形成统一且有效的解决方案。为了应对这种新型挑战,业内专家建议网站需要调整运营策略,不再仅仅针对人类用户优化内容和页面体验,而应兼顾AI访问需求,诸如设计适合机器处理的数据结构和接口、提供专门的API服务以实现监控和收费等。部分媒体已尝试与大型AI平台谈判达成内容授权合作,为自身内容使用设置合理收费标准,以期实现双赢局面。尽管如此,未来内容生态是否能够实现健康可持续发展,仍然取决于整个产业链的协同努力,包括法律层面对智能抓取行为的界定、行业对自主身份识别和访问控制的技术推进,以及社会对数字产权保护观念的普及提升。展望未来,随着AI在信息检索和内容生成领域日益扮演重要角色,我们可以预见网页流量结构将进一步分化,传统网页浏览可能被AI辅助查询所分担甚至替代。而网络内容生产者则需要拥抱更加开放且合作的内容生态,创新商业模式,在AI赋能的同时,也维护自身的权益和收益。
与此同时,监管机构也需加紧完善人工智能相关法规,推动形成公平合理的数据使用框架,确保数字内容产业链的繁荣和创新不受过度影响。总的来说,AI驱动的网络抓取流量激增,是互联网发展进入新阶段的标志之一,它呈现了技术进步带来的机遇与挑战交织的复杂局面。内容创作者、平台运营者、AI服务商及监管机构都需要以更加开放且务实的态度,共同应对数字经济的深刻变革,推动网络空间持续健康发展,实现技术与内容、创新与版权的良性共生。