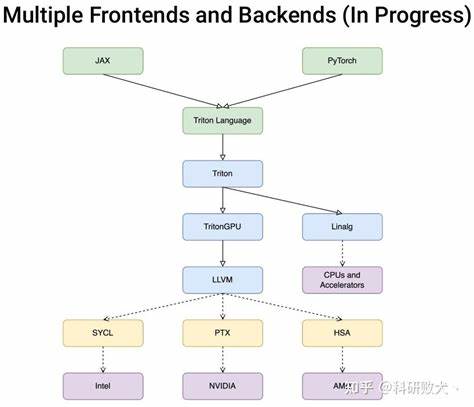
随着人工智能和深度学习的发展,GPU编程的重要性日益凸显。然而,传统的CUDA编程门槛较高,限制了许多研究者和开发者的创新速度。为解决这一难题,OpenAI在2023年推出了Triton,一门开源的类似Python的编程语言,旨在让没有CUDA经验的用户也能编写高效的GPU代码,实现简单易用与性能兼备的目标。 Triton的核心理念在于将GPU的编程抽象化,用Python的简洁语法降低开发难度。它让用户专注于任务的划分和调度,而自动完成线程内的代码优化,这极大地缩短了开发周期,提高了迭代速度。通过将Python代码即时转换成中间表示(IR),并在运行时优化后生成低级PTX代码,再通过LLVM及其子组件完成GPU的最终编译,Triton实现了高效且自动化的代码生成流程。
这种方法带来的直接优势是大幅降低了编写CUDA内核的复杂性。相较传统CUDA需要深入理解GPU硬件架构、线程管理及内存优化,Triton允许用户用熟悉的Python语法快速实现功能完整的内核代码。性能方面,只要用户掌握一定的调优技巧,其生成内核的性能能够逼近高级CUDA程序员所写的代码,展现出强大的竞争力。 尽管如此,Triton仍面临一些挑战。首先是调试难度较大,自动化优化过程对用户来说基本是黑盒,若代码性能未达预期,需深入分析PTX或LLVM IR,排查问题较为困难。此外,Triton当前支持的功能尚有限制,例如只支持大小为2的幂次方的tile,且不支持切片操作,这些限制在特定场景下影响灵活性。
Triton的应用价值突出在于快速原型开发和创建定制化内核。研究人员可以用它快速尝试新的算法思想和优化策略,验证可行性后再迁移到更复杂的CUDA代码中。同时,它能够填补主流库如cuBLAS或cuDNN未覆盖的新算子开发空白,加速高性能计算生态系统的多样化发展。 从性能角度看,Triton的优势不仅来自于自动化优化技术,还得益于基于LLVM的PTX生成,它能够实现如循环展开、矢量化加载存储等高级优化,甚至在某些情况下优于NVCC编译器。不同于库函数追求通用性,Triton可以专门针对具体场景生成精简且高效的代码,减少不必要的计算和内存访问,提升执行效率。 对比传统CUDA编程,Triton的调度方式和线程分配也有独特设计。
例如,Triton将程序标识符映射为CUDA的块索引,线程分配对应内的数组范围映射到线程索引,并通过掩码实现边界条件的处理,确保数据安全加载与存储。此外,Triton支持编译时常量处理技术,减少运行时计算负担,提高执行效率。 Triton的线程数量配置机制不同于CUDA,可在编译时确定Warp数量,运行时修改该配置不会影响内核执行,这表明其优化依赖于编译时参数,带来了灵活性代价。多个线程处理数据时,Triton会自动展开循环以提高效率,但当线程多于数据块大小时,部分线程可能没有有效工作,需用户合理设计线程和数据块尺寸以发挥计算资源优势。 向2D或更高维数据扩展时,Triton通过二维索引方式分配线程和数据块,可自动计算每个线程负责的元素数量,实现矢量化和循环展开的结合,提高内存访问效率和并行度。同时,Triton会采用共享内存和寄存器存储中间数据,应对转置、矩阵乘法等对布局变化有较高需求的算子。
在代码优化方面,Triton支持基于类型和大小的矢量化加载存储操作,利用PTX中类似ld.global.v4.b32的指令实现高吞吐量访问。但这一优化仅在数据边界内存访问满足对齐要求时生效,边界不确定时需添加掩码保护,否则无法矢量化。针对动态形状数据,Triton可以通过特殊设计,分离最后一个tile来实现大部分代码的矢量化,兼顾性能和安全。 Triton还大幅简化了复杂的共享内存同步与线程通信。以归约操作为例,Triton内建tl.sum函数会自动采用warp内shuffle指令实现快速规约,并借助共享内存完成线程块内部汇总,省去了繁琐的同步控制代码。多线程块归约时,Triton自动调用原子加操作完成最终累积,大大提高编程效率。
在内存管理上,用户无需显式控制数据在寄存器、共享内存或全局内存的具体位置,Triton会根据操作类型智能推断。需要共享内存支持的操作如归约、转置和矩阵乘法会自动申请共享内存保持数据一致性和高效访问。对单纯的加载和存储,数据默认保存在寄存器中,保证最快的访问速度。 此外,Triton还支持多种数学指令,包括高效实现各种常用函数。以sigmoid为例,Triton生成的代码采用快速近似指数计算方法,兼顾性能和精度。相比NVCC常规实现,Triton在保证结果一致性的前提下,某些指令使用了快速数学操作符号,微优化了计算效率。
在深度学习加速领域,Triton对张量核心(Tensor Core)的利用是其重要亮点。用户通过定义矩阵乘法内核,Triton可自动调用底层高效的点积指令,提升半精度浮点计算性能。虽然编写方式仍保留Python语法简洁度,但生成的PTX代码却充分利用了硬件专有指令,兼顾通用性和性能。 Triton的设计理念和实践对GPU编程范式带来重要启示。它表明优化可以被有效地封装和自动化,将复杂的性能调优工作隐藏在编译器后端,让开发者能够更专注于算法设计和任务调度。此外,快速迭代能力有助于加快研究节奏,使具备基础编程知识的人员也能较快掌握GPU内核编程,实现性能上的跨越。
然而,Triton目前仍属于高速发展的新兴技术,社区生态和文档支持尚在逐步完善。性能调优依赖经验积累,调试效率尚需提升,部分限制性特征亟待突破。未来,Triton有望在融合更多高级优化策略的同时,扩展更多算子支持和调试工具,进一步降低门槛,推动GPU计算向更广泛的应用领域渗透。 总体而言,OpenAI Triton作为2023年GPU编程领域的重要创新,为高性能计算引入了Python化的编程体验,以自动化优化和灵活调度实现了性能与易用的平衡。对于深度学习研究者、算法工程师和GPU开发者而言,掌握Triton无疑是提升编程效率和创新能力的利器。未来随着不断发展完善,其在GPU加速生态中的角色将日益关键,为人工智能等前沿领域的计算性能提供强劲助力。
。