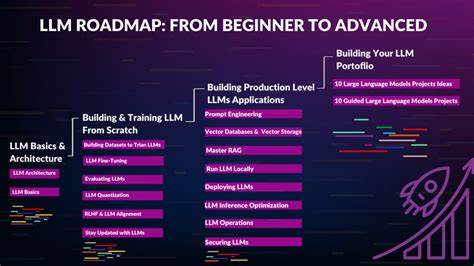
随着人工智能技术的迅猛发展,尤其是大型语言模型(LLMs)在自然语言处理领域展现出的巨大潜力,越来越多的计算机专业背景的学习者渴望深入了解和掌握这一前沿技术。然而,LLMs的学习门槛较高,相关知识体系庞杂且复杂,很多人面对浩如烟海的机器学习前置课程感到困惑和迷茫。因此,制定科学合理的学习路线,既抓住核心本质,又注重实操落地,成为成功掌握LLMs的关键。本文将基于Osman Ahmad M. Osman在2025年6月发布的著名学习路线图,结合理论与实践,剖析如何从零开始逐步建立LLMs相关技能,直至能够自主搭建、训练与部署真实的语言模型。首先,要理解LLMs,必须具备扎实的基础知识。大多数人误以为需要数学博士或掌握深奥的机器学习算法才能入门,但事实并非如此。
真正重要的是对线性代数、概率论及编程实现有清晰直观的理解。通过3Blue1Brown制作的线性代数系列视频,可以有效构建矩阵变换的视觉化直觉,这为后续理解神经网络的运算打下基础。MIT的线性代数公开课(由Strang教授讲解)则提供了更为系统和严谨的理论支持。编程方面,推荐学习Karpathy的Micrograd教程,这是一套手把手带你从零打造自动微分引擎的课程,能帮助你深刻理解神经网络训练的内核机制。完成后可尝试构建一个简单的多层感知器(MLP),并用真实数据集如MNIST进行训练。进入语言模型的核心——Transformer结构学习阶段,许多学习者常被其专业术语吓倒,误以为它非常复杂。
事实上,Transformer就是由一系列矩阵乘法和注意力机制构成的模块化堆叠。学习时应重点培养直觉,通过3Blue1Brown与Jay Alammar的图文视频,理解注意力机制如何赋予模型动态聚焦输入信息的能力。Stanford CS224N提供的自然语言处理课程,深入讲解了Transformer的原理与细节,帮助理论和实践结合。此阶段推荐阅读《Attention Is All You Need》论文,这篇论文虽内容专业,但具备良好直觉基础之后阅读,会极大加深理解。实践上,可以尝试复刻一个迷你版的GPT模型,甚至挑战替换不同的分词器,如BPE或SentencePiece,强化编码和解码的理解。随后,学习扩展至大规模训练与模型扩容相关知识。
LLMs性能提升的关键在于“规模定律”,即模型参数规模、训练数据量与计算资源三者之间的关系。推荐深入阅读《Scaling Laws for Neural Language Models》和《Chinchilla》两篇论文,以理解隐含的数学原理及其现实意义。并非所有人都有条件使用大型集群师训练完整模型,但学习分布式训练的范式和技术(如数据并行、张量并行和流水线并行)是关键技能。利用HuggingFace Accelerate等开源工具进行多GPU训练实践,是理解大模型训练挑战的有效途径。细节上的实验,如调节批量大小、累积梯度等,能让你体验显存限制及训练稳定性的实际问题。此外,模型的微调及对齐技术也不容忽视。
大规模预训练模型虽然语义宏大,但往往需要通过基于人类反馈的强化学习(RLHF)或宪法式AI(Constitutional AI)等方法进行任务定制,解决安全、合规及性能适配问题。通过研读相关论文和博客了解小样本微调策略及RLHF背后的工作机制,有助于深入理解模型应用落地。Low-Rank Adaptation(LoRA)和其高效变种QLoRA更是当下最热门的参数高效微调技术。掌握手动实现LoRA,将其集成进HuggingFace预训练模型,针对实际应用场景进行微调,能够极大提高模型的实用性与推广价值。最后,进入部署与推理优化阶段。速度、内存占用和响应时间是生产环境评估大型模型的重要指标。
了解诸如FlashAttention等高效注意力机制优化论文,结合量化技术,使得模型推理达到亚秒级响应,更符合实际应用需求。全链路掌握推理优化技术,不仅提升用户体验,也降低系统成本。综上所述,学习大型语言模型不是简单的观看教程或阅读论文,而是循序渐进,理论与实践结合的系统工程。通过分阶段学习线性代数、概率论,掌握自动微分与神经网络基本原理,深入理解Transformer架构,攻克大规模训练难题,精通微调及模型对齐,最终实现推理优化和真实部署,能够培养出真正具备核心竞争力的AI人才。积极动手构建项目,在错误和调试中成长,将使你的理解更加深刻且持久。追随这条经过验证的学习路线,利用推荐的优质资源,你不仅能穿透LLMs领域的迷雾,还能在人工智能浪潮中抢占先机。
未来已来,掌握LLMs,便掌握了开启人工智能时代的钥匙。









