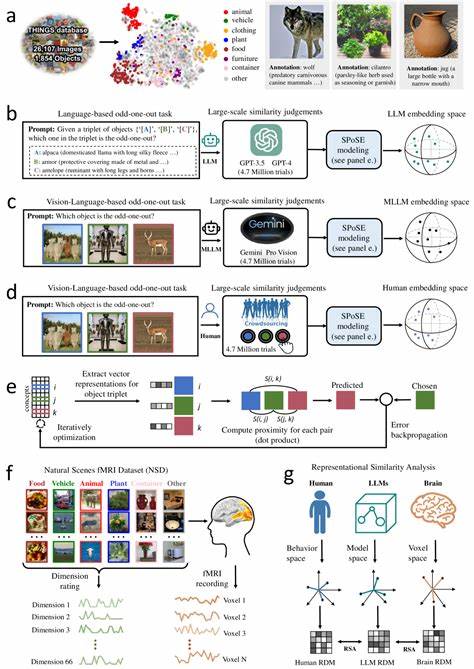
在当今的人工智能领域,大语言模型(LLMs)已成为推动技术变革的核心力量,尤其是当这些模型具备多模态处理能力时,展现出更加类似人类认知的物体概念表征。这种现象不仅加深了我们对人类认知机制的理解,也为构建更具智能与灵活性的人工系统提供了理论支持和实践基础。 人类在日常生活中对物体的理解是多层次、多维度的,这包括形态、功能、语义属性以及它们与环境和行为的关系。传统的机器学习模型主要依赖单一模态的信息处理,比如仅从文本或图像中提取特征,这在理解物体的复杂语义时存在局限。相比之下,多模态大语言模型通过同步学习语言和视觉信息,不仅提升了对物体的感知能力,也促使模型形成了更加逼近人类认知的物体概念结构。 最新的研究表明,当这种模型处理海量的图文数据时,它们能够自发地构建低维度的嵌入空间,这个空间具有良好的稳定性和可解释性,且与人类脑部特定区域的神经活动模式高度对应。
这意味着模型中的物体表示不仅在功能上类似于人类认知中的概念,而且在结构上也保留了人脑处理信息时的重要特征。这种跨领域的对应为认知神经科学和人工智能之间搭建了一座桥梁。 通过行为实验与神经成像技术的结合,科学家们收集了数百万条模型生成的三元组判断数据,将这些数据转化为能够反映物体间相似性和差异性的嵌入向量。在这个多维空间里,物体根据其语义和感知特征自然聚类,形成清晰的类别边界。这种表现不仅和人类基于经验得出的分类结果高度一致,还揭示了模型能够抽象和泛化概念的潜力。 更进一步的分析显示,模型中的各个维度具有一定的可解释性,比如有些维度对应物体的大小、形状、用途或与生命体相关的属性。
这种维度的可解释性增强了模型的透明度,也为未来在智能系统中引入符合人类认知规律的推理和决策机制奠定了基础。 除了理论层面的启示,这种人类般的物体概念表征在实际应用中同样价值巨大。它能够推动自动驾驶、智能机器人、图像识别以及人机交互等领域的技术进步。举例来说,在自动驾驶系统中,多模态理解能力使得系统能够更准确地识别和预测周围物体的行为,从而提升安全性。在智能机器人中,这种概念表征有助于机器人更好地理解环境,做出符合人类期望的动作决策。 尽管多模态大语言模型表现出了让人惊叹的能力,但目前仍存在一些挑战和研究空白。
比如,如何进一步提高模型在复杂场景下的泛化能力,如何减少模型对偏见和误导信息的敏感性,以及如何实现模型与人类认知过程的更加精准对齐。这些问题正催生着跨学科的深入研究,推动从神经科学、认知心理学到人工智能工程的多方合作。 此外,伦理和隐私问题也日益受到关注。多模态模型在处理涉及敏感内容的视觉和语言数据时,需要保障用户数据的安全和隐私,同时保证模型不会产生有害或偏颇的结果。建立透明、负责任的模型训练和使用机制,是未来发展的关键一环。 总结来看,多模态大语言模型中人类般的物体概念表征的自然生成,是当代人工智能向认知智能迈进的重要标志。
它不仅为理解人类思维机制提供了新的视角,也为打造更接近人类智能的机器奠定了坚实基础。随着技术的不断进步和理论研究的深入,我们有望见证更加智能、便捷和安全的人工智能应用落地,深刻影响未来的社会和生活。