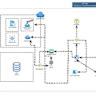
在当今人工智能领域,自然语言处理技术正迅猛发展,尤其是大型语言模型(LLM)的崛起,为各类文本生成和智能问答带来了革命性的变革。然而,随着信息量激增和应用场景复杂化,单一纯生成模型面临着知识时效性不足、生成内容可信度难以保证等挑战。检索增强生成技术(Retrieval-Augmented Generation,简称RAG)应运而生,成为连接检索系统与生成模型的关键桥梁,极大提升了语言模型在知识密集型任务中的表现。Awesome-RAG项目是目前GitHub上最全面、系统的RAG资源整合平台,涵盖了从基础理论、工具库、框架到先进研究与实战指南的丰富内容,成为业界学习和开发RAG技术的宝库。 检索增强生成是一种创新范式,通过在推理阶段从外部知识库检索相关信息,辅助语言模型生成更加准确、上下文相关且具备实时性的数据内容。相较于传统的语言模型,RAG能克服知识过时与幻觉(hallucination)问题,提高回答的准确性与可靠性。
Awesome-RAG巧妙地汇集了最新公开的研发工具、论文资源、评测方法以及社区实践,为广大研究人员和开发者搭建了极具价值的知识生态。 该项目详细罗列了众多开源工具和商用平台,如CustomGPT.ai、LangChain、Haystack、LlamaIndex等,涵盖了使用SDK搭建定制化RAG系统的全过程。这些工具支持多语言、多格式文档的检索处理,配合向量数据库(Vector Databases)如Pinecone、Weaviate、Qdrant等,为高效存储与相似性搜索提供坚实后盾,极大简化了复杂的检索部署与管理工作。 在Embedding模型方面,Awesome-RAG整合了OpenAI text-embedding-3、Cohere Embed v3、SentenceTransformers、BGE家族等尖端技术,这些模型在语义矢量化时展现出超强的表达能力,既适合密集检索也满足稀疏检索需求。此外,项目还提供丰富的检索方法介绍,包括密集检索(Dense Retrieval)、稀疏检索(Sparse Retrieval)及混合检索方案,以及对应的优化策略和再排序技术,帮助实现最佳的检索效果。 在RAG的架构设计层面,Awesome-RAG涵盖了众多创新方案,如微软的GraphRAG利用知识图谱增强推理能力,DeepMind的RETRO实现了大规模的检索缓存,Meta的RAG-Fusion融合了多源检索技术。
这些前沿方法有效提升了整体生成质量与上下文关联性,彰显了RAG发展多元化与高度技术融合的趋势。 安全与隐私方面,Awesome-RAG同样重视风险防范,集成了诸如OWASP安全框架、数据脱敏工具、模型劫持防御等多项行业标准与最佳实践,确保RAG系统在企业级应用中不因安全漏洞而暴露风险。此外,开源安全工具链如NeMo Guardrails和LLM Guard为开发者提供了灵活可配置的防护能力,有效制约潜在的不良生成行为。 在评测与优化领域,本项目涵盖了包括RAGAS、RAGBench、BeIR等多种综合评估指标与基准测试,辅助开发者准确把握模型与检索的性能边界。同时通过案例分享与成本计算器,帮助团队在性能、质量和成本之间做出权衡,实现可持续发展。 随着多模态数据的兴起,Awesome-RAG同步推进图像、表格和文本多源信息融合的研发,包括基于CLIP的视觉文本检索和SAM-RAG的自适应多模态RAG框架,展现了RAG技术在跨领域应用中的巨大潜力。
复杂任务更倾向于采用Plan-then-RAG等先规划后检索的策略,有效提升了复杂推理的效率与准确率。 该项目不仅聚焦技术细节,更注重社区建设与教育推广,丰富的课程教程、研究报告和技术讲座覆盖了从入门到高阶的各类需求。配合活跃的论坛和Slack、Discord社区,Awesome-RAG正成为全球RAG技术交流与创新的中心之一。其持续更新的研究论文库和新闻资讯帮助使用者紧跟行业脉动,掌握最新科学成果和落地案例。 综上所述,Awesome-RAG作为一个集大成的RAG资源库,不仅推动了检索增强生成领域的知识体系完善,还为实际项目应用提供了强有力的工具支持。对于创业者、技术开发者以及学术研究者而言,深入了解和利用该平台所提供的丰富资源,将极大提升创新能力与产品竞争力。
随着人工智能需求向更精准、高效、可控方向演进,RAG技术及其生态的价值将日益凸显,Awesome-RAG无疑是通往该新纪元的重要起点。未来,随着模型和检索算法的不断进化,结合图谱和多模态信息的深度融合,检索增强生成技术必将引领智能内容生成进入一个全新的高度。探索Awesome-RAG的世界,正当其时。