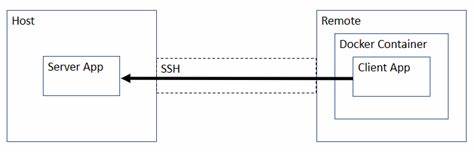
随着人工智能技术的不断发展,基础模型已成为推动自然语言处理、计算机视觉等多个领域变革的重要力量。Qwen3-Next系列作为最新一代基础模型,聚焦提升模型的效率和能力,特别是在处理极长文本和实现大规模参数调度方面取得了突破。它不仅在性能上超越了前代产品,更大幅降低了训练和推理的计算成本,成为人工智能研发的新标杆。Qwen3-Next的设计理念围绕极致的参数效率展开,最核心的创新之一是引入了混合注意力机制,结合了Gated DeltaNet与Gated Attention,这种混合形式替代了传统的标准注意力机制,更加高效地捕捉上下文信息,提高了模型对超长文本的处理能力。混合注意力的引入不仅优化了计算资源的利用,也增强了模型的学习能力,使得Qwen3-Next能够在保持较小计算量的情况下,仍能准确理解和生成丰富的文本内容。另一项引人注目的技术创新是高稀疏度的专家混合模型(MoE)。
在Qwen3-Next中,MoE层的激活比率极低,达到1:50的水平,这意味着在模型运行时只有极少部分的专家网络被激活,从而极大减少了每个token的计算浮点操作数(FLOPs),实现了显著的计算效率提升同时不降低模型容量。这种高稀疏性设计使得Qwen3-Next在处理大规模模型时能够维持高性能,优化了资源分配,适合大规模并行训练和部署。多Token预测(MTP)技术则是Qwen3-Next提升预训练效率和推理速度的关键,它通过同时预测多个token,显著加快了模型的训练和生成过程,从而缩短了模型达到最佳性能所需的训练时间。这一技术不仅加速了模型预训练阶段的收敛,也提升了推理阶段的响应速度,为用户带来更流畅的交互体验。除了上述核心技术外,Qwen3-Next还融合了多项针对稳定性和训练效率的优化。例如,零中心和带权重衰减的层归一化技术,能够稳定训练过程,防止梯度爆炸或消失,确保模型在大规模训练中的鲁棒性。
Gated Attention和其他细节改进进一步提高了模型的表达能力和泛化性能。基于这些架构创新,Qwen团队打造了Qwen3-Next-80B-A3B模型,它拥有80亿参数,但在任何时刻仅激活3亿参数,实现了极致的稀疏性和效率。这款模型在下游任务中表现优异,超过了先前的Qwen3-32B模型表现,同时训练成本仅为其十分之一,大幅降低了模型开发的门槛和花费。更加值得关注的是,Qwen3-Next-80B-A3B在处理超过32000个token长度的上下文时,其推理吞吐量提升了10倍以上,这意味着它能够更加高效、准确地完成长文本理解和生成,满足从复杂文本分析到对话系统的多样化需求。Qwen3-Next系列的推出,代表了基础模型在超长上下文处理能力与参数稀疏激活技术领域的领先地位。通过严格的架构设计与细节优化,Qwen3-Next不仅实现了性能的跨越式提升,还展现了未来人工智能模型发展的重要方向,即在保障智能水平的前提下,通过智能稀疏与混合计算实现极致的效率优化。
从实际应用角度来看,Qwen3-Next系列广泛适用于自然语言生成、机器翻译、问答系统、文本分类等多种场景,适应能力和扩展潜力巨大。其开放源码的策略也促进了学术界与工业界的协作创新,形成了良性生态圈。全面支持Hugging Face Transformers平台,使开发者能够便捷地集成Qwen3-Next模型到现有项目中,极大方便了模型的训练、微调和推理部署。此外,Qwen3-Next的相关代码和文档不断更新,社区活跃度高,开发者可以获得丰富的资源支持和技术交流空间。值得期待的是,随着技术的进一步成熟和应用案例的丰富,Qwen3-Next系列或将催生更多具有创新意义的新型智能产品和服务,引领人工智能向更高效率、更强智能的未来迈进。总结来看,Qwen3-Next系列利用混合注意力、高稀疏度MoE、多Token预测以及一系列优化技术,突破了传统模型的限制,实现了超长文本的高效处理和极致的计算资源节约。
它不仅提升了模型性能,更为大规模智能系统的部署提供了坚实基础,是当前及未来基础模型领域不可忽视的重要里程碑。在人工智能飞速发展的时代,Qwen3-Next为科研人员和工程师提供了强大工具,助力解决更复杂的语言理解和生成任务,推动技术创新和产业变革。 。