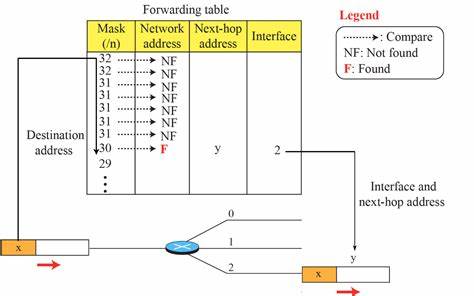
地址匹配作为地理信息系统、物流配送和智能导航等领域的核心技术,一直是研究和应用的重点。传统的地址匹配方法通常依赖于字符串的精确比对,然而现实生活中的地址信息常常存在拼写错误、多余词汇、顺序混乱甚至格式不统一等问题,这给匹配带来了极大的挑战。为了克服这些困难,容错Trie(fault tolerant trie)作为一种强大且灵活的数据结构,逐渐成为地址匹配领域的新宠,开创了更加高效和容错的匹配方式。 Trie是一种字典树结构,专门用来存储具有公共前缀的数据集合。在地址匹配中,Trie能够根据地址的层级和地理结构,将地址拆解为若干层级的词汇节点,形成一棵从具体到泛化的分支树。例如,从门牌号、街道名到城市和国家等,Trie的层级划分与地址的地理层次天然契合。
每个节点不仅保存该词汇信息,还记录其是否为地址的终止节点,以及该节点所涵盖的地址数量等属性,从而实现了对地址集合的快速定位和统计分析。 然而,简单的Trie虽然能快速进行精确匹配,却无法应对现实中地址数据的各种"杂乱"情况。地址中可能出现额外的词汇,如"FLAT A"、"ANNEX"等附加信息,或用户在输入时出现遗漏、错误甚至词序错乱。如果依赖严格的字面匹配,往往导致大量匹配失败,影响用户体验和系统的准确性。针对这一问题,容错Trie的设计理念便是赋予Trie一定的"容错"能力,允许在匹配过程中灵活跳过、忽略或调整输入的词汇,以找到最接近且合理的匹配结果。 容错Trie的核心机制之一是在遍历地址词汇时允许某些规则下的词汇跳过。
具体来说,若输入地址尾部出现多余词汇,系统可以选择忽略它们,只要能够在Trie中匹配到一个计数超过一定阈值的节点,说明该节点代表的地址有较高的匹配概率。同样,当中间出现不匹配的词汇时,容错机制允许跳过该词汇,尝试重新连接到Trie的其他分支,以避免因为少量词汇差异丢失整个匹配结果。此外,如果在匹配过程中已经遇到了一个终端节点且该节点无子节点,则系统可以忽略后续的多余词汇,这对处理附加信息特别有效。 这一机制不仅提升了地址匹配的召回率,也增强了模型对输入噪声的容忍度。更重要的是,容错Trie保持了Trie结构高效的匹配特性和层级信息优势,使得在数据规模不断增长的背景下依然具备实用性和可扩展性。经由实践验证,使用容错Trie进行地址匹配的系统在多个实际场景中表现出色,尤其适合处理复杂、格式多样的真实地址数据。
在具体应用方面,容错Trie已被集成到多种现代数据处理平台和扩展库中。以DuckDB为例,其社区扩展包splink_udfs中就包含了基于容错Trie的地址匹配功能,用户可以通过简单调用实现高质量的地址匹配服务。此外,英国的开源项目uk_address_matcher也正在采用这种方法,致力于提供快速且准确的地址匹配解决方案。这些工具不仅方便开发者将容错Trie技术应用于实际业务,也推动了整个地址数据处理生态的升级。 从技术意义上讲,容错Trie的引入代表了地址匹配算法从单一字符串比对向结构化模式识别的演进。它结合了Trie的分层索引优势和灵活的容错策略,有效解决了地址数据的非标准化问题。
未来,随着人工智能和大数据技术的发展,容错Trie还可能结合更多语义分析、机器学习等方法,实现更智能、更精准的地址解析与匹配。 具体而言,利用容错Trie能够帮助各领域打破地址数据孤岛,实现异构地址库之间的高效对接。例如,电商物流中的地址标准化,智慧城市中的地理信息管理,甚至公共安全领域的应急定位服务,都可以从中受益。容错Trie不仅提升了匹配的准确度,降低了因地址错误带来的物流成本和服务风险,同时也改善了终端用户的使用体验,促进了数字经济的健康发展。 综上所述,容错Trie在地址匹配中的应用展示了数据结构设计与实际业务需求的深度融合。它不仅解决了传统匹配方法的瓶颈,更为智能地址处理提供了坚实基础和广阔前景。
随着相关技术和工具的不断完善与普及,容错Trie将成为地理信息系统及相关领域的关键技术之一,引导地址匹配向更智能、更灵活、更高效的方向迈进。 。