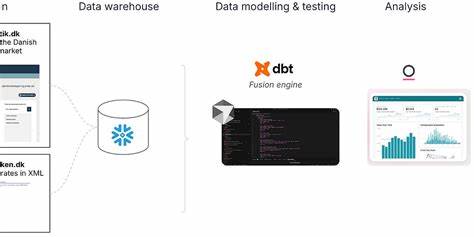
随着大数据时代的加速发展,数据工程师和分析师面临着日益复杂的数据处理和建模挑战。传统的手工数据建模往往耗费大量时间和人力,同时代码质量及项目结构的合理性也直接影响数据资产的可维护性和扩展性。近年来,人工智能逐步渗透到数据工程领域,其中在dbt(数据构建工具)中的应用更是推动了数据建模的新变革。借助AI的强大能力,可以极大地提升数据建模的效率、准确性和智能化水平。本文将深入探讨如何利用AI工具有效支持dbt中的数据建模工作,从数据导入、项目结构规划、清洗转化,到构建数据集市和语义层,实现数据驱动的商业价值最大化。首先,数据建模的首要环节是数据准备。
举例来说,从丹麦金融协会的公开房地产数据中,我们可以下载多份CSV文件,包含房屋上市情况、贷款报价、销售周期以及城市和邮编的销售价格等信息。将这些数据存入Snowflake是一种现代云数据仓库架构中的常见实践。数据入库后,初步的统计概览有助于识别缺失值和异常字段。人工智能在此环节能够发挥显著作用。通过向AI工具提供样本数据,智能分析其字段类型及潜在问题——例如数字字段被错误存储为字符串、日期格式不统一或者数据出现不合理的替代值。以“销售周期”字段为例,本应为数值型的天数却被储存在字符串中,这对后续的聚合计算如平均销售周期统计会造成阻碍。
AI助手建议在建模时使用数据类型转换宏,既提升了代码复用性,也保证了字段类型的统一处理。此外,针对季节性和时间序列分析至关重要的季度字段,部分数据采用“2021K3”此类非标准字符串作为标识。此类格式易导致时间排序错误。AI推荐将季度字符串解析成标准日期格式,或者拆分成年和季度两个字段进行更严谨的时间处理。完成数据探查和预处理设计后,下一步便是合理规划dbt项目结构。一个良好的项目结构不仅方便协作,也便于未来扩展。
人工智能能根据提供的表名和业务主题自动提议分层目录架构,划分为如staging、intermediate和marts等模块,分别对应数据清洗、业务逻辑中间层和最终面向业务的数据集市。例如,数据表划分出市场时机、贷款和房屋销售三大类,智能生成对应文件夹,同时创建sources.yml文件映射到Snowflake的具体数据源,保证项目源的清晰和可追踪。数据建模核心阶段则是构造清洗转化的staging模型及后续的业务数据集市marts。在staging层,AI基于数据样本智能生成SQL代码,自动实现字段类型转换、异常数据处理及专项宏定义。比起人工繁琐编码,AI能迅速完成标准化工作。随后,结合业务需求明确对不同维度数据的关联,如房屋类型、区域及时间维度,将销售价格、销售周期和贷款类型的多个表通过left join逻辑安全组合,保证数据的完整性且不遗漏任何关键指标。
若存在部分组合无数据,AI还会提醒制定合理的缺失值处理策略。完成数据集市建设,下一步是打造语义层,为BI分析和自然语言查询奠定基础。语义层通过将复杂的数据模型封装为具备清晰描述的指标和维度,极大地降低了业务人员使用门槛。借助dbt的metrics.yml文件以及人工智能辅助生成的度量指标,数据团队能快速制造出丰富、合理的度量集合。AI甚至可以根据样本数据和业务语境创新延伸指标,激发新的洞察思路。为了实现可复用且规范的文档编写,AI同样能根据数据样本撰写清晰的表和字段说明,增强数据模型的可理解性与透明度。
综上,AI在dbt数据建模各阶段扮演关键助手角色。从初始的数据一致性检查到代码自动生成,再到模型结构设计与元数据管理,AI大幅度提升了建模速度与质量,节省了大量重复劳动。尤其是利用融合了代码上下文的编辑器扩展,结合AI提示,开发者可以在开发环境中实时获得语法检查、智能建议与数据预览反馈,使数据流水线构建更为流畅高效。伴随着AI技术和数据工程工具的深度结合,未来的数据建模趋势将更加智能化、自助化,也更能贴合业务诉求。数据团队应积极拥抱AI辅助工作流,打造稳定并可持续演进的数据资产体系,从而驱动企业实现更敏捷的数据驱动决策。随着后续文章探讨使用AI进行数据测试和监控,以及构建面向终端用户的语义查询层,完整的人工智能驱动数据工程解决方案即将揭晓。
总而言之,将AI引入dbt数据建模,不仅是技术革新,更是推动数据价值释放的重要路径。