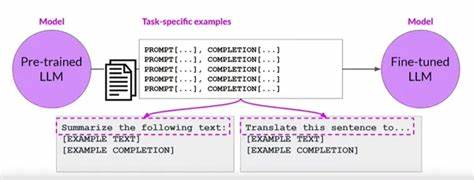
在当今人工智能快速发展的时代,大型语言模型(Large Language Models,LLMs)因其强大的语言理解和生成能力,成为推动自然语言处理技术进步的核心。然而,传统基于逐字预测的训练方法在处理复杂语义和高层次概念时存在显著局限性,难以实现真正的人类级别理解和推理。这种基于单个词或字符的分解方式导致模型难以把握整体概念的内在连贯性,制约了智能系统的发展。面对这一挑战,概念感知微调(Concept-Aware Fine-Tuning,简称CAFT)技术应运而生,它通过多词序列的联合训练方法,重新定义了大型语言模型的微调方式,极大增强了模型对抽象概念和复杂语义结构的认知能力。传统的语言模型主要依赖于下一词预测机制,即模型通过依次预测序列中的每个词,逐步学习语言规律。这种方法虽然在一定程度上能够捕捉局部依赖关系,但在理解诸如“核糖核酸”这样整体语义明确的词组时,却不得不将其拆分成若干独立的词素,例如“rib”、“on”等碎片,无法整合为一个连贯的语义单元。
结果,模型难以准确把握组合所蕴含的深层语义,影响推理和生成的质量。概念感知微调技术的核心创新在于允许模型在微调阶段直接训练多词序列的联合预测,从而提升对整体概念的理解能力。这一方法打破了多词预测以往只出现在预训练阶段且计算成本高昂的局限,使得更多研究者与工程师能够在模型微调时享受到多词学习的优势。通过直接学习跨词的语义联系,模型不仅能够更好地抓住文本的全局语境,还能在多元化任务中表现出更强的泛化能力。具体来说,CAFT技术通过设计多词目标函数,结合高效的训练策略,使模型在学习过程中能够同时考虑多个相邻词的语义联合概率。这种联合训练方式加强了模型对长远依赖和复杂概念的捕捉,避免了传统方法中词素分割带来的语义碎片化问题。
大量实验结果表明,采用概念感知微调后的大型语言模型,在文本摘要、问答系统、专业领域知识挖掘以及生物医药等多个实际应用场景中均取得显著性能提升。例如在生物医药领域,CAFT技术极大增强了模型对蛋白质设计和基因序列分析的理解能力,提高了实验预测的准确度和效率。此外,概念感知微调还推动了模型在理解隐含逻辑和推理链条上的能力发展,使其在更复杂的认知任务中表现出色。这种广泛的效果验证,印证了多词联合训练的重要性,也为未来语言模型的创新提供了坚实的理论和技术基础。在技术实施层面,CAFT不仅要求模型具备更高的计算效率,也需要改进的优化算法以支持多词目标的稳定训练。研究团队通过优化梯度计算和参数更新机制,降低了训练过程中的资源消耗,使得大型语言模型的微调更加经济且易于推广。
与此同时,开放源码和数据集的发布极大推动了学术界和工业界对这一技术的深入探索与应用开发,形成了积极的生态环境。展望未来,概念感知微调技术的推广有望引领新一代更加智能和具备深层语义理解能力的语言模型,从而广泛应用于智能助理、教育辅导、医疗诊断、自动翻译等多个领域。随着研究的不断深入,结合其他前沿技术如知识图谱、强化学习和多模态学习,语言模型将实现更接近人类认知模式的语义处理和推理能力。这将为人工智能的进一步普及和普惠奠定坚实基础,推动社会各行各业的数字化转型升级。综上所述,概念感知微调作为大型语言模型发展的关键里程碑,不仅破解了传统单词预测的限制,还开启了模型泛化能力和理解深度的新篇章。通过多词联合训练,它赋予模型强大的概念识别和整合能力,极大提升了人工智能系统的智能水平和应用价值。
面对未来,我们期待该技术助力构建更加智慧、精准与高效的智能生态,推动人类文明进步进入崭新的智能时代。