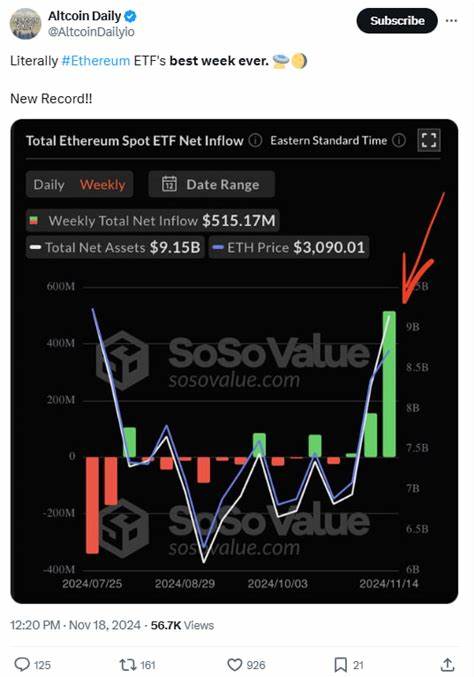
随着大语言模型(LLM)和人工智能技术的快速发展,本地推理解决方案逐渐成为保障用户隐私、降低使用成本和提升响应速度的关键方向。Shimmy作为一款开源且超轻量的本地AI推理服务器,凭借仅5MB的二进制文件大小和高兼容性,正在行业内引发广泛关注。Shimmy不仅是对传统大型AI推理软件的有力替代,更以其隐私优先设计、强大的GPU支持和MOE(混合专家模型)混合推理能力,为开发者提供了一个高效便捷的本地AI框架。本文将全面剖析Shimmy的技术亮点和应用前景,助力大家深入理解其背后的核心价值。Shimmy的设计理念聚焦于极致轻量化和零配置体验。与竞争对手Ollama体积高达680MB相比,Shimmy只有约5MB,这让它在下载、安装和启动速度上占据绝对优势。
启动时间短至不足一秒,内存使用控制在50MB上下,极大减轻了硬件负担。这种极致优化得益于它基于Rust语言开发,充分利用了Rust在内存安全和异步性能上的优势,同时集成了llama.cpp作为推理核心。Shimmy内置完全开源的OpenAI API兼容接口,方便用户无缝衔接现有开发工具和SDK,支持Python、Node.js、curl等多种主流环境,以及VSCode Copilot和Cursor IDE等主流AI开发环境。用户只需修改API端点,便可瞬间启用本地推理,大幅度降低接入门槛。Shimmy支持自动发现本地GGUF格式的模型文件,兼容Hugging Face缓存目录、Ollama模型存储路径和自定义本地文件夹,极大提高模型管理的灵活性。值得一提的是,Shimmy也自动识别并适配LoRA微调权重,助力用户轻松加载各种定制化模型。
针对硬件加速,Shimmy内置多种GPU后端支持,涵盖NVIDIA CUDA、Vulkan、OpenCL以及苹果生态的MLX,实现跨平台高性能推理。尤其针对资源受限设备,Shimmy通过MOE混合专家模型技术,智能将模型不同层分配到CPU和GPU,最大限度提升运行效率同时降低显存占用。这种独特的CPU+GPU混合方案,让用户能够在普通消费级硬件上运行70亿至数百亿参数的大语言模型,突破了传统大型模型对高端GPU需求的门槛。Shimmy的本地推理模式最大化保障数据隐私。所有推理任务均在用户设备本地完成,无需上传数据到第三方服务器,这对企业级用户和注重信息安全的个人用户尤为重要。它免去了复杂的API密钥设置和按使用量付费的经济负担,支持无限制调用和自定义负载均衡,打造始终在线、低延迟、可靠的推理环境。
开发者社区对Shimmy的贡献推动了其持续演进。项目维护者采用严格的测试方案,包括性质测试、跨平台验证和代码质量门槛,确保每个版本的稳定性和性能。一系列插件、部署模板和文档帮助初学者快速上手,同时为经验丰富的工程师提供高度可定制化的底层能力,支持Docker、Kubernetes及云端本地混合部署。市场上对更轻量、安全和灵活的本地推理工具需求日益强烈。Shimmy凭借其开源MIT许可协议,保证了用户自主权和创新自由,避免了市场上常见的"免费试用"或"付费锁闭"陷阱。通过持续的赞助支持,Shimmy承诺免费永久维护,构建了一个透明、友好的开发生态。
总结来看,Shimmy是当下本地大语言模型推理领域的革新力量。它用极小的体积和完善的功能,打破了传统大模型推理部署的复杂壁垒,为注重隐私的用户及小型开发团队提供了坚实保障。得益于其丰富的GPU支持和智能混合推理架构,不论在macOS、Windows还是Linux平台,Shimmy都能带来快速响应和稳定可靠的体验。未来,随着更多先进模型与硬件的兼容加入,Shimmy有望成为本地私有推理领域的行业标杆。对于希望控制数据隐私、降低运行成本且追求极致性能的开发者来说,Shimmy无疑是最值得尝试的开源解决方案。通过本篇解读,希望你能全面了解Shimmy的技术架构与生态优势,抓住新时代AI推理本地化趋势下的机遇,将其融入你的项目与产品开发,开启高效、安全的AI应用新时代。
。