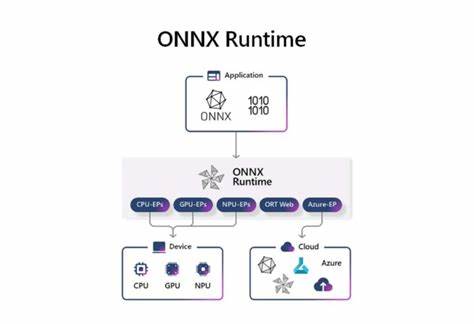
在数字化和算法主导的时代,声音成了新的战场。少于十年的时间内,语音合成与声音克隆技术从科幻走入商业化应用,许多平台开始用人工合成的"虚拟声音"配合有声内容,承诺以更低成本、更快速度覆盖海量书单。然而,尽管机器可以模仿语调、节奏和情绪的表面形态,人工智能旁白在讲述真正的人类故事上存在根本性短板。理解这些短板,对于作者、配音演员、出版从业者和有声书听众,既是辨别未来趋势的必要准备,也是探讨伦理与行业规范的起点。声音只是载体,故事是关系。人类叙述的力量,来自于叙述者在语言之外的投入:身体记忆、生活经验、情感共鸣以及对文本意图的深度理解。
人声传达的不仅仅是字面信息,而是潜台词、停顿、呼吸和不完美的抖动,这些微小的变化往往携带最深的情感。配音演员通过对角色的内在化,将文本转化为一个具体的存在:谁在讲、在何种情境下、为什么选择这种语气。人工智能可以重现声音的轮廓,但无法真正"成为"那个讲述者,无法在讲述的过程中被文本改变、被情感触动,因而失去了人类叙事的本质要素。意图与责任是不可外包的要素。讲故事不仅是技术任务,更是价值判断。配音演员在演绎时承担着对作者文本与听众情感的双重责任:既要忠于作者意图,又要以同理心负责地传达给听众。
机器没有意图也没有道德责任。它在没有情感投入的前提下复刻声音,可能会忽略文本中的微妙关怀或对敏感题材应有的处理。更糟糕的是,声音克隆可能在没有授权或充分告知的情况下被用于政治宣传、商业误导或伤害性内容,造成伦理与法律风险。"恐怖谷"效应也在听觉领域显现。人们对接近但不完全等同于真人的声音,容易产生不适与疏离感。心理研究与机器人学文献中早已描述,越像人类的非生命体在某些细微处偏差越大,导致强烈反感。
对于有声书这种高度依赖情感连接的媒介来说,听众一旦察觉声音背后没有活生生的经验与关怀,沉浸感便难以维系。长此以往,平台以低价大量投放合成旁白,可能会侵蚀听众对有声书整体品质的信任。从产业角度观察,声音克隆推动的成本压缩与规模化有其经济吸引力,但也带来劳动力市场的重构风险。叙述者群体长期以来以自由职业者为主,工作稳定性本已脆弱。若版权持有者、出版平台或大厂优先采用人工合成声音,真实配音演员面临被挤压的危险。不仅如此,声音的无偿复制还可能连带影响配音的品牌价值与个人声誉。
即便当下有声称通过授权或分润补偿原声表演者,但商业模式不透明、权益保障不足,仍然难以从根本上缓解不平等。技术并非全无价值。语音合成在辅助性功能、无障碍服务及快速原型制作方面有实际用途。对视障者的语音化内容、快速生成草稿版旁白、为教学与信息检索提供便捷都属于合理应用场景。关键在于如何划清工具使用与替代创作的界限,以及如何在技术推广中建立知情同意、合理补偿和不可克隆的创作者主张。比如在商业化克隆之前,应有明确的授权流程、版税分配机制和对被克隆者的终生保护条款。
声音的"身体经验"无法被算法完全复制。叙事源自身体:呼吸的频率、疾病后的沙哑、年岁的粗糙、突然哽咽时的停顿,这些都源于个人生命过程。它们不仅是声音的物理特征,更是情感与历史的痕迹。人类听惯了带着这些痕迹的声音,会在潜移默化中构建信任和亲密感。机器制造出的"无病呻吟"或"过度完美"的口吻,长期接触会削弱这层信任,导致听众对情绪内容的敏感度下降,最终伤害整个文学与口述传统。伦理问题是不可回避的焦点。
声音克隆牵涉个人肖像权、人格尊严和族群表征风险。配音演员可能被迫在条款中接受声音被无限复制的条款,或在生前签署后被遗产继承人卖断权利。已故表演者的声音被"复活"用于商业产品,听起来虽然熟悉,却缺少已故者的意愿与参与,这种"殭尸化"的使用引发深刻的伦理质疑。行业需要通过法律与行业规范来界定声音权的边界,建立严格的授权、显性标识及回溯可控机制。面向未来的可行路径需要多方协作。首先,政策与法律应跟进技术发展,明确声音权利的归属、克隆使用的许可条件以及侵权责任。
对于未经授权的声音复刻,应设立快速申诉与下架机制,以防止滥用。其次,行业内部要设计公平的补偿体系。若平台确有理由用合成声音完成大量低成本工作,原声表演者应享有合理的分成或许可费,并可选择撤回许可。建立行业联盟与最低报酬标准,可在一定程度上保护中小配音演员的基本生计。再者,出版社、制作方与作者在签署有声书合同时,应增加关于合成声音使用的透明条款,并在作品封面或元数据中明确标注声音来源,以便听众做出知情选择。个人层面上,配音演员可以通过提升不可复制的技能保持竞争力。
那些源于深度文本理解的人声表演、现场参与录制、互动式敘事和跨媒体演绎(如与影视、广播剧、现场朗读会相结合)的服务,更难以被简单的语音克隆替代。建立个人品牌、发展听众社群和提供差异化体验(例如签名朗读、见面会、定制化内容)都是有效策略。作者与出版方也应重新认识人声的市场价值,并愿意在有声版权上投入合理资源,以维护内容的艺术价值。听众也有发言权。消费行为能够驱动市场方向。优先支持由真实配音演员完成的作品、在平台上给予高评分和评论、参与众筹与直接购买有声内容,都是对人声叙事的实际支持。
听众的偏好若明显向着高质量人声倾斜,平台在商业考量上也会更谨慎地大规模采用合成声音。科技公司与平台有责任在产品设计中植入伦理考量。将"合成声"与"真人声"在目录中区分开来、在播放页显著标注声音是否合成、预设不得在未经授权情况下生成或售卖人声克隆,并为被克隆者提供实时控制权限,能减少滥用。同时,推动声音识别与水印技术的发展,使得合成或克隆的音频具备可追溯性,有助于监管与司法取证。文化维度的思考同样重要。人类通过声音传承历史、建立家庭记忆、完成仪式性的互动。
把讲述与温度替换为冷冰的算法,虽然在商业上可能暂时获得效率,但会逐渐侵蚀公共文化生活中的"肉身经验"。我们要问:在追求规模化与低成本的同时,我们是否愿意为失去那份由声音带来的亲密与伦理负责。保护人类叙述的场域,不仅是保护一群职业者的生计,更是在守护一种社会共鸣的可能性。归根结底,人工智能旁白无法讲出真正的人类故事,因为故事不是单纯的信息传递,而是关系的建立与生命经验的传递。声音背后的身体、意图与责任是机器难以拥有的核心。面对技术的快速推进,社会应以更敏感的伦理感、明确的法律规范和更公正的产业安排来回应。
支持真实的配音表演、提升对创作者权利的法律保护、促使平台承担更多透明与责任,都是在为未来保留人类叙事的空间。当听到一个温暖的夜读声、父亲的临别录音或一段全力投入的朗读时,听者体内会有某种东西被唤醒。那不是完美无缺的音色,而是缺陷中包含的真诚、破绽里显现的历程。人类的故事,从来不是被完美复制出来的结果,而是经由生命的磨损、悔恨、欢笑和爱的反复铸就。若要珍惜这些故事,我们就必须意识到:技术可以扩展艺术的表现形式,但不能替代人类在叙事中所承担的那份肉身与灵魂。 。