近年来,随着人工智能和机器学习的飞速发展,对比学习作为一种强有力的表征学习方法,受到了广泛关注。尤其是在图像、文本等领域,自监督对比学习由于不依赖标签而能够充分利用大量无标注数据,显示出强大的实用价值。然而,长期以来关于自监督对比学习的理论基础仍存在诸多未知。最新研究表明,自监督对比学习实际上在一定条件下可以被看作是有监督对比学习的一种近似,从而为理解其性能提供了坚实的理论支撑。本文将深入探讨自监督对比学习与有监督对比学习之间的联系,解析其数学原理、几何结构以及对少样本任务的影响,进而为机器学习研究者和从业者提供有益启示。首先,理解自监督对比学习与有监督对比学习的差别至关重要。
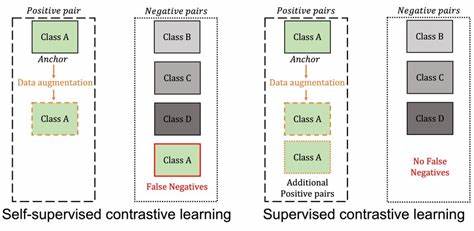
有监督对比学习依赖于标签信息,通过对同一类别的样本进行聚合(正样本)与不同类别样本进行分离(负样本),以学习区分性强的高质量特征表达。相比之下,自监督对比学习通过数据增强技术创建正样本对,利用未标注数据挖掘潜在的语义信息,但不使用显式的类别标签。传统观点认为自监督方法虽然实用,但难以达到有监督方法的判别力。最新的理论成果表明,自监督对比学习的目标函数在语义类别数目较大时,能够近似一种称为“负样本有监督对比损失”(NSCL)的有监督损失函数,这种损失忽略了同类别内部的对比,只关注负样本之间的区分。研究通过严格的数学证明指出,当类别数量增加时,自监督方法和这类有监督方法间的目标差异逐步缩小。这意味着在语义类别充足的环境下,自监督对比学习天然具备近似有监督学习的能力。
该理论突破对学界和工业界均有深远意义。进一步从几何角度解析,自监督与负样本有监督对比学习的最优解表现出特有结构,表现为数据增强造成的“增强塌缩”、同类别样本的聚合以及类别中心组成的单纯形等角紧框架结构。这种结构不仅保证了类别间的区分度最大化,还提升了表示的稳定性和泛化能力。通过对这些几何性质的理解,研究者能够设计出更高效的网络架构和训练策略,以充分挖掘对比学习蕴含的信息。本研究还引入了新的少样本泛化误差界,揭示了线性探测头在小样本标注任务中的表现由特征的两种变异度决定:一是类内散布,二是沿类别中心线的方向性变化。结果表明,随着标注样本数量的增加,类内散布对误差的影响逐渐减弱,而方向性变化成为主要影响因素。
这一发现解释了为什么利用对比学习学到的表征,可通过简单线性探测获得令人满意的少样本分类性能,为实际应用中少样本学习问题提供了理论指导。值得关注的是,实验结果也强有力地验证了理论分析的准确性。通过系统训练和测试,研究团队发现自监督和负样本有监督对比学习损失之间的差距确实以类数的倒数速度降低,二者损失值高度相关,且最小化自监督对比损失会自动使对应的负样本有监督损失接近其直接最小值。同时,提出的少样本误差界在实际线性探测中表现出较高的预估精度,体现了理论与实践的高度一致。从应用角度看,这一系列发现极大地增强了自监督对比学习的可信度和实用性,使其在无需大量标注数据的条件下,实现接近甚至超越传统有监督方法的表现成为可能。特别是在图像识别、自然语言处理和推荐系统等领域中,结合该理论能够设计更具鲁棒性和泛化能力的模型,推动真实环境下AI系统的部署和优化。
同时,为未来的发展指明了方向。随着数据规模和语义类别的进一步扩展,自监督对比学习或将逐渐取代传统有监督方法成为表征学习主流,尤其在标签资源稀缺的场景中发挥更加重要的作用。此外,研究对数据增强策略和样本选择优化的启示,将引导学者进一步探索模型设计的新思路,提升对比学习算法的效率和性能。总结来看,自监督对比学习与有监督对比学习间的近似关系,不仅揭开了长期悬而未决的理论谜团,也为表征学习领域注入了新的活力。通过对目标函数、几何结构和少样本泛化性能的综合分析,推动了算法理论与应用的深度融合。未来,随着更多研究的推进,我们有望见证对比学习在人工智能各领域更加广泛的应用和突破。
。