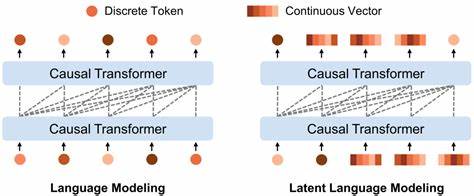
近年来,随着人工智能尤其是自然语言处理技术的快速发展,语言模型在文本生成、理解、对话系统等领域取得了前所未有的进步。然而,传统的自回归语言模型由于一次生成一个单词的限制,难以实现对整句语义和文本结构的全局把控,导致生成文本在连贯性、逻辑性上存在一定短板。为了解决这一痛点,来自COLM 2025会议的一项创新研究成果 - - Stop-Think-AutoRegress语言扩散模型(STAR-LDM)应运而生,开启了语言建模的全新篇章。 STAR-LDM大胆融合了潜在扩散规划技术与自回归生成方法。其核心创新在于引入"停-思-自回归"机制,即在生成过程中暂停令牌的逐字生成,通过扩散模型在潜在语义空间中进行深度思考和规划。这种间断式的生成策略赋予模型在生成任何具体文本前,能够先在连续的潜在空间中形成整体的语义蓝图,从而提升文本一致性和内容丰富度。
该机制打破了传统由左至右顺序生成带来的局限,使语言模型具备了全局规划能力,进而在故事叙述、论证逻辑以及常识推理等方面表现卓越。 从技术角度看,潜在扩散规划是一种通过扩散过程不断优化潜在变量表达的生成方法。它模仿人类"思考"的方式,在各种可能表达之间反复迭代和调整,最终生成更加精准且符合语义预期的表示。结合自回归模型的强大序列预测能力,STAR-LDM实现了连续空间中的全局规划与离散空间的逐步生成的有机融合。研究实验证明,STAR-LDM在多个自然语言理解基准测试中显著超越同等规模的传统自回归模型,在故事连贯性和常识性推理任务中,更是达到了超过70%的LLM裁判对比胜率。这个数字充分显示了其在语言生成质量上的巨大优势。
此外,STAR-LDM的架构还支持通过轻量级分类器实现灵活的文本属性控制。相比于传统需要重新训练大规模模型来实现风格调整或内容引导的方法,STAR-LDM允许简单调节控制器来实现细粒度的文本生成属性管理,如情感色彩、叙述风格和主题倾向等。这不仅大幅降低了调整成本,也保证了生成文本的流畅度与属性控制之间获得了平衡,提升了模型在实际应用场景中的适用性和用户体验。 从应用场景来看,STAR-LDM为智能写作助手、对话系统、智能推荐等多种领域带来了突破性进展。其能够在生成长文本时保持前后文一致、逻辑合理的优势,尤其适合新闻生成、小说创作、技术文档编写等需要深度语义理解和复杂结构支持的任务。同时,可控的文本生成能力满足了市场对个性化内容的强烈需求,帮助企业和创作者更加高效、精准地实现内容生产。
面对当下语言生成技术巨头如GPT系列和BERT系列,STAR-LDM以其独特的"停-思"机制和潜在扩散规划展现了差异化优势。它解决了传统自回归生成中的"短视"问题,提升了模型的语义视野和推理深度,使文本生成过程更加智能和符合人类认知规律。此外,该模型的可控性设计为未来语言模型的个性化和定制化方向提供了重要参考和技术储备。 值得一提的是,STAR-LDM的研究团队严格遵循COLM会议的伦理规范,保证技术的开发和应用符合道德标准,促进人工智能的健康发展。这也凸显了科研界日益重视技术创新与社会责任并重的趋势。 展望未来,结合潜在扩散技术与自回归生成的语言模型有望进一步融合更多多模态信息,如图像、音频等,推动跨领域智能文本生成能力升级。
同时,随着计算力提升和算法优化,STAR-LDM的效率也将持续改进,以适应更大规模数据和更高复杂度任务的需求。其所带来的全局规划和动态思考能力,或将引领新一代自然语言生成系统迈入更加智能和富有创造力的时代。 总结来看,Stop-Think-AutoRegress语言扩散模型代表了自然语言生成技术的重要突破。通过创新性地在自回归生成中插入潜在语义空间的扩散规划阶段,STAR-LDM成功实现了文本生成的全局语义规划与细致逐步输出的结合。这不仅提升了生成文本的质量和连贯性,也极大增强了模型的可控性,为未来自然语言处理领域注入了新的活力与可能性。随着相关技术的不断完善与推广,STAR-LDM有望成为智能写作、对话交互乃至更广阔语义理解领域的重要基石,推动人工智能语言理解和生成走向更高峰。
。