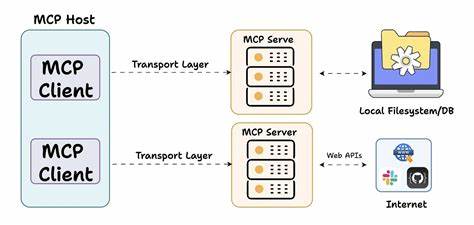
在云原生时代,Kubernetes作为容器编排的核心平台,极大地方便了分布式应用的部署和管理。然而,在实际项目中,数据共享与同步成为了一个不容忽视的挑战。尤其是从Git仓库、S3存储、HTTP接口或者SSH服务器获取数据时,传统方法往往依赖于init容器、sidecar容器或自定义任务来完成。这些方式虽然能够实现功能,但却带来了多份数据冗余、存储资源浪费以及管理复杂度的提升。SharedVolume作为一款新兴的开源Kubernetes操作器,旨在解决上述痛点,简化数据卷的同步操作,提升集群资源利用率。SharedVolume通过定义共享卷(SharedVolume)或集群共享卷(ClusterSharedVolume)对象,能够自动从指定的数据源拉取并持续同步最新数据,确保集群内只有一份数据副本。
这一机制使得各个Pod只需简单添加注解即可挂载共享的卷,大幅度减少了操作复杂性和存储开销。SharedVolume支持多种主流数据源,包括Git仓库、Amazon S3、HTTP服务器以及通过SSH协议访问的数据源,极大地增强了数据接入的灵活性。相比传统同类工具,SharedVolume最大的优势在于其自动化的同步机制和跨命名空间共享能力。用户无需编写复杂的同步脚本或者定时任务,操作器会持续监控数据源的变化,基于事件驱动的方式及时更新集群中的数据副本。与此同时,跨命名空间共享功能极大地方便了不同业务线或团队间的数据共享,避免了多份数据的复制与管理难题。从使用者角度来看,部署SharedVolume非常简便。
首先需要通过Kubernetes的自定义资源定义(CRD)创建SharedVolume或ClusterSharedVolume对象,配置源数据的类型和访问参数。随后,相关Pod只需通过注解引用对应的共享卷,操作器会自动将最新的数据挂载进容器文件系统,确保数据始终保持最新且一致。这种解耦的架构设计不仅降低了应用对数据访问的耦合度,还提升了整体系统的可维护性和扩展性。SharedVolume的实际应用场景非常丰富。对于需要频繁更新配置文件、静态资源或代码库的微服务应用,SharedVolume能够保证所有实例同步使用相同版本的数据,避免因数据不一致引发的运行时错误。对数据科学和机器学习领域而言,通过SharedVolume同步共享数据集,可以极大提高训练任务的资源效率和协作体验。
此外,运维团队也可以利用SharedVolume实现敏捷的版本管理和灾难恢复策略,增强集群的稳健性和可观测性。尽管SharedVolume目前尚处于Beta阶段,但其已经展现出强大的功能潜力和良好的用户反馈。项目提供了详细的文档和示例,帮助用户快速上手和集成。在未来版本中,预计会进一步完善多源数据同步的性能优化、权限管理和失败恢复机制,满足更多复杂生产环境的需求。支持开源项目的发展对整个社区都有积极影响。如果您认为SharedVolume能够提升您的Kubernetes数据管理效率,欢迎通过GitHub为项目点星,助力其获得更多关注和贡献。
通过共享与互助,云原生生态将更加繁荣,也让开发者和运维人员的工作更轻松顺畅。总结来说,SharedVolume作为一款创新的Kubernetes操作器,精准解决了多数据源同步与跨Pod共享中的难题。其自动同步机制和简洁使用方法,使得数据管理变得更加高效和可靠。随着云原生应用复杂度不断提升,像SharedVolume这样的工具将成为提升集群资源利用率和运维效率的重要利器。建议所有涉及数据同步与共享需求的Kubernetes用户密切关注并尝试使用SharedVolume,为打造稳定高效的云原生环境贡献力量。 。