近年来,人工智能技术迅速崛起,尤其是在自然语言处理和机器学习领域的突破,使得基于网络内容训练的AI模型层出不穷。然而,随着AI公司大量利用互联网公开内容作为训练素材,内容创作者与AI企业之间原有的“流量换内容”协议逐渐瓦解,内容生产者的收益和权益面临严重威胁。作为全球领先的云服务和网络安全供应商,Cloudflare积极回应这一挑战,推出了专门针对AI爬虫的收费机制,试图为内容创作者争取合理的版权价值回报,推动互联网环境向更健康、公平的方向发展。Cloudflare CEO Matthew Prince在多个场合强调,过去近30年来,搜索引擎与网站之间存在一种默契:搜索服务提供商通过索引网站内容,向网站导入流量,从而助力内容创作者获得广告或订阅收入。但随着人工智能技术兴起,谷歌、微软、OpenAI等大厂采用自动化爬虫大规模抓取网页内容用于模型训练,却未必为内容方带来等价流量与收益,反而形成了“剥削式采矿”,让内容生产者在付出巨大劳动的同时,难以获得应有回报。此现象背后隐藏的深层次问题是,所谓“公平使用”的法律解释逐渐倾向于认可公开网页内容可被AI训练,这让司法体系尚无力保护内容所有者权利,导致内容创作者陷入无偿付出的困境。
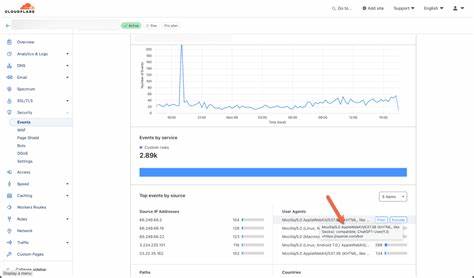
Cloudflare对外发布的数据显示,许多AI爬虫对网站的内容请求次数远远超出其回传的实际访问流量。例如,Anthropic的AI平台Claude在监测期间的HTML页面请求数与实际带来的网站流量请求比例高达近7.1万比1。其他AI企业如OpenAI、微软、谷歌等,也展现出明显的“爬取多、引流少”特征。这种严重失衡不仅伤害了内容创作者的利益,也对互联网生态的持续繁荣构成长期威胁。为应对这一局面,Cloudflare与全球内容提供商及部分AI公司合作,启动了“按爬取付费”(Pay per crawl)的技术解决方案。该机制通过网络请求的协商流程,实现了AI爬虫使用内容时必须明确支付意向,若未支付则被服务器返回“402 Payment Required”响应,自动阻止非付费访问。
Cloudflare同时扮演收款方及技术基础设施的角色,为出版商管理爬虫访问权限,提供封锁、免费或收费等多样化策略选项,助力内容方安全合理地掌控自家内容的爬取与商业利用。此外,Cloudflare正在逐步推动该服务的私测,计划让更多出版商采纳这一模式。部分知名出版机构已通过诉讼和协议与AI企业达成内容授权及付费协议。例如微软于2024年11月与出版社HarperCollins达成为期三年的AI训练内容使用许可,支付金额高达5000美元,体现了市场对版权价值的认可与回归。尽管这一费用相较于AI训练模型巨额收益仍显有限,但无疑是版权保护在AI浪潮中的重要突破。推出“按爬取付费”模式的意义不仅在于保障创作者收益,更在于推动互联网生态体系的长期可持续性。
随着人工智能技术渗透生活各个层面,内容生产与数据使用的边界日益模糊,单凭法律难以快速调整,技术手段成为缓解矛盾的重要路径之一。Cloudflare作为网络交通的核心中介,利用其独特优势在协议层面创建公平交易环境,有望引起行业广泛关注与效仿。未来,随着越来越多内容创作者通过主动设置爬虫付费门槛维护权益,AI公司也将被迫重新审慎考虑数据获取的成本与合规风险,促使产业链各方建立更加平衡的共赢合作关系。这对鼓励优质内容创作、维护知识产权尊严以及推动AI科技健康发展均有积极推动作用。总体来看,Cloudflare的新举措象征着互联网历史上的又一个关键转折。面对人工智能带来的机遇与挑战,以技术创新主动赋能版权保护和生态治理,成为当下及未来推动行业可持续成长的重要路径。
内容创作者、技术企业与监管机构间围绕数据权益的博弈仍将持续,但Cloudflare打造的AI爬虫收费门槛无疑树立了行业范例,指明了AI时代内容生态保护的新方向。随着全球范围内版权保护意识加强以及AI技术监管趋严,预计此类“按爬取付费”技术将日益普及,为丰富多彩的互联网内容保驾护航。内容创作者有望摆脱无偿被剥夺权益的困境,AI企业也将在更加公平合理的规则框架下创新发展,推动人类知识共享与技术进步达到新的高度。云端守护者Cloudflare此举不仅是对AI时代版权挑战的回应,更是互联网开放与尊重原创价值之间平衡的创新探索。未来网络世界的繁荣前景,也将依赖于此类技术生态变革的持续深化与推广。