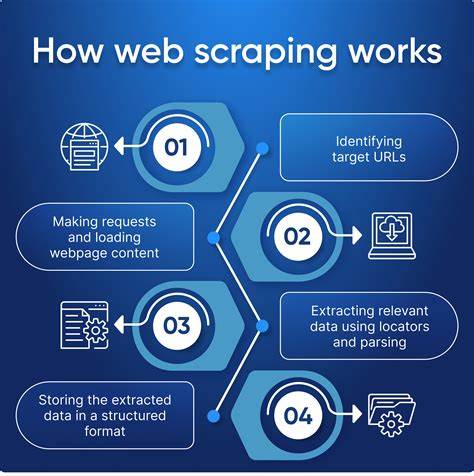
随着互联网的飞速发展,网页数据成为企业和研究者获取市场洞察、竞争情报与用户行为分析的重要资源。然而,网页数据抓取并非易事,尤其面对复杂的动态网站和频繁更新的内容,传统的抓取工具往往力不从心。ScrapingDuck应运而生,作为一款专业的网页数据抓取API,旨在为用户提供稳定、精准、强大的数据采集服务,助力各类规模的数据项目顺利完成。ScrapingDuck是一款针对现代动态网页量身打造的API服务,支持JavaScript渲染,能够处理SPA(单页应用)、React和Vue等前端技术生成的内容。它通过真实的无头浏览器环境还原网页,确保采集到的HTML数据完美匹配用户在浏览器中看到的页面。这种对客户端渲染的全面支持极大提高了数据的完整性和准确性,弥补了传统爬虫因无法执行JavaScript而错失信息的缺陷。
在应对反爬机制方面,ScrapingDuck同样表现出色。它采用自动代理轮换策略,通过强大且分布广泛的住宅及数据中心代理池,巧妙规避IP封禁和访问限制。同时,用户也可根据需求调整请求时延与资源加载,降低目标网站反爬风险,确保采集流程平稳进行。这种智能代理管理与反检测的组合为用户提供了极大的灵活性和可靠性,让繁复艰难的数据采集变得轻松可控。ScrapingDuck还为用户提供高度的浏览器操作自由度,支持模拟点击、滚动、文本输入等互动行为,完美适配需要用户交互的复杂页面,如无限滚动列表或多步骤表单等。这使其不仅能够采集静态数据,更能实现对动态内容和深层数据的精准捕捉,满足不同业务场景下的多样化需求。
在性能和扩展性方面,ScrapingDuck凭借其高可用的基础设施支持大规模并发处理,适合从小型项目到数百万页面的海量数据抓取。其API设计简洁易用,提供明确的状态码、请求计时及使用报告,方便用户实时监控数据采集状态与效率。未来还将支持Webhook和调度功能,进一步强化自动化和集成能力,提升整体使用体验。从行业应用角度看,ScrapingDuck广泛服务于价格监控、潜在客户挖掘、市场信息跟踪和房地产数据采集等领域。企业能够借助其稳定的渲染HTML,精准提取JS重度依赖的网站信息,快速聚合多区域数据,实时掌握行业动态与竞争关系。ScrapingDuck的客户反馈也极为积极,许多用户称其替代传统浏览器集群后极大提升了数据采集成功率和开发效率,强大的渲染控制功能让爬虫开发者能够轻松获得理想的DOM结构,保障下游数据解析的准确性和一致性。
综合来看,ScrapingDuck不仅实现了网页数据抓取的技术突破,更通过合理定价策略满足不同规模客户需求,做到功能全面且价格透明。其免费试用无须信用卡的友好政策降低了使用门槛,吸引了大量初创和中小企业尝试并应用其服务。ScrapingDuck的使命是让强大的网页数据抓取变得人人可及,无需担心代理配置、浏览器维护与反爬难题,从而让用户将精力专注于数据分析和业务洞察。随着数字经济的不断深入,ScrapingDuck所提供的稳定、高效且灵活的接口服务无疑将在数据驱动决策与智能应用领域发挥越来越重要的作用。对于追求数据精度和采集效率的开发者和企业而言,ScrapingDuck是一款值得信赖的优质选择。未来,随着功能的不断完善与行业的持续拓展,ScrapingDuck将继续引领网页数据抓取技术的发展趋势,帮助更多用户轻松驾驭网页信息的海量价值,实现商业智能的飞跃。
。