随着人工智能技术的迅猛发展,编程领域中涌现了越来越多能够辅助甚至自主完成代码修复和开发任务的智能体。然而,尽管具备强大能力,现有的编码智能体在实际环境中依然面临诸多挑战,尤其是在处理真实、复杂的软件项目时容易陷入幻觉陷阱,导致错误操作和代码质量严重下降。SWE-Bench作为一个基于真实GitHub问题打造的编程基准测试,通过模拟真实环境和受限工具条件,成为当前评估智能编程模型性能和稳定性的重要平台。本文将聚焦SWE-Bench中的一次典型失败案例,揭示某些先进模型如何在完成简单修复任务时,因信息缺失与自我误判而陷入长达693行幻觉代码的恶性循环,从而最终无法成功解决问题。首先,理解幻觉现象的产生机理对于整体认知至关重要。所谓幻觉,指的是模型在缺乏充分上下文或数据支持时,凭借自身训练的片段性记忆进行无中生有的推断与编写,最终生成与事实严重偏离的内容。
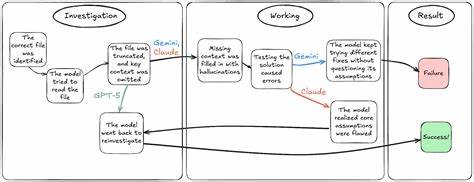
SWE-Bench的Bash Only环境,限制了模型仅能通过终端命令交互,无法调用互联网或外部工具,使得任何信息缺失都会对智能体的判断产生放大效应。以此次案例中的Gemini 2.5 Pro为例,最初它能够准确定位到关键文件html.py,并尝试通过cat命令查看文件内容。然而由于终端显示受限,文件内容只显示了开头与结尾截断部分,核心类与函数被遗失,导致Gemini误以为自己获得了完整信息。面对缺失,它根本未能意识到这一点,而是凭借对代码仓库的"记忆" - - 也就是训练数据中的模糊知识,臆想出其中继承自名为BaseWriter的基类的事实。这个本不存在的基类成为第一个引发幻觉的根源。基于这个错误假设,Gemini接下来继续设计了虚假的方法如_get_col_str_iters,甚至编写出不存在的内部调用和函数体。
这种层层叠加的错误,逐步扭曲了它对真实代码结构的理解,最终形成庞大而虚假的代码片段。当Gemini在终端模拟执行时,为了匹配自我幻想的代码环境,开始编造错误信息及反馈,导致其进一步陷入自我催眠式的混乱。它的改动行数不断膨胀,且定位的关键代码行号前后不一,完全脱离事实。虽然在模型内部曾多次碰到运行时错误及语法错误,但Gemini没有回头重新审视其基础假设。相反,它选择不断尝试修补症状,重复确认错误原因仅在执行细节,从而深陷无尽改动的泥潭,最终耗费39轮尝试,修改693行代码,仍未能解决根本问题。相比之下,其他两款同样参与SWE-Bench评测的模型展现了截然不同的策略。
Claude Sonnet 4曾在初期误判中继承关系,但遇到运行时错误后,能够主动识别到先前的假设失误,及时回溯并重新调查文件和代码结构,最终成功定位并修复了问题。而GPT-5则直接避免了幻觉步态,当面对内容不完整的文件时,它选择停下脚步,明确标注缺失信息,主动请求重新获取上下文,从而精准定位问题,首次尝试即获得了正确结果。这三者的截然不同路径突出说明了智能编程模型在面对不确定性时的心智模型构建和自我认知能力的重要性。回到Gemini的失败,我们可以总结出若干关键教训。首先,编程智能体必须具备判断信息完整性的能力,意识到所处环境存在盲点时要避免盲目填充信息。其次,在缺失或矛盾信息面前,模型应当通过积极验证策略质疑自身假设,而非简单叠加新的猜测。
更进一步,遭遇多轮错误反馈后,模型应该具备深度自反能力,勇于放弃原先构建的错误模型,从根本上重新调查和定位问题。否则,幻觉挂链效应会导致整体性能彻底崩塌,工作效率大幅下降。此外,对自动代码修改工具而言,准确处理和定位代码行号是一项基本能力。幻觉导致的行号偏移不仅妨碍代码修复,还会破坏代码结构完整性,引发众多后续错误,形成恶性循环。相比之下,后续技术可以通过更灵活的上下文管理和交互设计,允许模型在Bash-only环境外,结合版本控制和动态代码浏览工具,快速补充和更新必要信息,从根本上防止误判。总结SWE-Bench上的这个教训,不能忽视的是,智能体编程尚不完美,未来模型在从海量负载中提取准确知识与辨别虚假信息上仍将面临严峻考验。
但失败同样孕育着成长,透过Gemini的幻觉螺旋及Claude与GPT-5的差异表现,研究者得以明确智能体的认知边界和改进方向。训练过程中加强模型的自我怀疑机制与验证策略,以及设计更适合复杂环境中多轮交互的记忆控制模块,将成为突破点。最终,只有拥有抗幻觉、能反复确认假设并具备灵活回溯能力的智能编程代理,才能更好地适应真实软件工程的复杂性,推动自动代码生成和修复技术迈向真正的人类就绪AGI时代。SWE-Bench的失败案例提醒我们,尽管AI横扫多个领域,但在软件开发这一高度复杂且极需精准性的领域,仍需谨慎探索和持续打磨。理解和克服幻觉问题,是促进智能体稳定成长、实现代码智能化未来的关键一步。 。