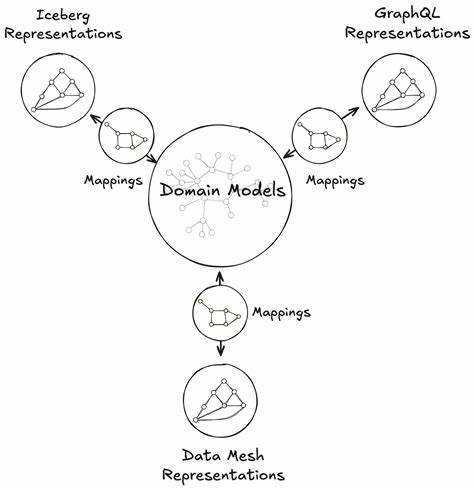
在当今数据驱动的数字时代,如何高效整合和利用海量数据成为企业制胜的关键。Netflix作为全球领先的流媒体巨头,其背后的数据技术体系尤为引人关注。Netflix提出并构建了统一数据架构(Unified Data Architecture,简称UDA),通过“模型一次建立,应用无处不在”的理念,实现了数据模型的高度复用与业务多场景覆盖。本文将深入解析Netflix的UDA,探讨其设计理念、系统架构、技术挑战与解决方案,揭示其如何推动数据驱动的企业创新和运营优化。 Netflix的统一数据架构诞生于其对海量数据处理和实时分析的迫切需求。传统的数据架构往往存在数据孤岛、模型重复构建和维护成本高昂等问题,这些难题在Netflix这样规模庞大的企业尤为突出。
UDA的核心目标是通过构建统一的数据模型,实现一次定义、多处使用,从而提升数据资产的复用率和质量,降低数据整合和分析的复杂度。 UDA的设计理念中,“模型一次建立”强调数据科学家或工程师只需在单一平台或环境中定义数据模型,模型定义包括特征提取、数据清洗、转换逻辑等。完成模型构建后,模型即被纳入统一管理体系,并通过高效的调度和数据服务层,支持不同业务线、不同应用场景调用。这种设计极大减少了模型重复开发的工作量,且提升了数据一致性和实时性。 技术上,Netflix的UDA构建在云原生架构基础上,结合了大数据存储、流式计算、批处理及机器学习平台。大量数据通过Kafka等消息队列进行流式采集,经过Flink或Spark Streaming完成数据预处理和特征构建,再存储至分布式数据湖如S3或作为OLAP引擎供实时查询。
模型训练与调优环节基于Netflix广泛使用的开源机器学习平台进行,保障模型质量及迭代效率。 UDA还实现了模型管理与服务的自动化。通过统一的元数据管理平台,系统对模型版本、依赖关系和使用状况进行监控与管理,保障模型的可追踪性和合规性。模型一旦上线,可通过REST API或内部微服务框架,快速将模型能力赋能至推荐系统、内容个性化、用户行为分析、安全监控等多维度业务应用中,实现业务智能化升级。 以推荐系统为例,Netflix通过UDA可以确保推荐模型基于最新用户行为数据实时更新,无需重复手动调整数据流程。统一模型定义支持多样化算法实验和迭代,显著提升推荐质量与用户满意度。
此外,UDA推动内容生产、广告投放及风险防控等领域的数据协同,为全链路数据治理和智能决策搭建坚实基础。 UDA的发展过程中也面临诸多挑战。跨团队跨领域的数据标准化与治理复杂度高,如何保证数据权限安全与隐私合规依然是核心课题。Netflix通过引入细粒度访问控制、多层加密机制及严格的审计流程,增强数据安全保障。同时,公司持续优化数据平台的性能与扩展性,以满足不断增长的数据规模和计算需求。 未来,Netflix计划进一步深化UDA能力,结合人工智能与自动化运维技术,打造更加智能化、自动化的数据全生命周期管理平台。
利用自适应资源调度和自动模型优化,实现数据资产的最大化价值释放。同时,推动开源社区合作,分享经验与技术,促进整个数据生态体系的发展。 总的来说,Netflix的统一数据架构UDA通过“模型一次建立,应用无处不在”的设计理念,成功解决了大规模数据管理与应用的瓶颈,构建了高效、灵活且安全的数据平台体系。其先进的技术实践和运营经验为全球数据驱动企业提供了宝贵借鉴。随着数据技术的不断演进,UDA模式有望成为更多组织实现数字化转型的重要支撑基础,推动数据智能化进程迈向新高度。









