矩阵乘法作为现代计算领域中最基础且最关键的算法之一,涵盖了从科学计算、图像处理,到人工智能等广泛领域。无论是深度学习中的全连接层,还是Transformer架构中的注意力机制,矩阵乘法无疑扮演着不可替代的角色。计算性能的提升直接关系到模型训练和推理的速度,进一步决定了人工智能应用的效率和效果。在当今硬件快速发展的大环境下,如何实现跨多个计算平台的高效矩阵乘法核,成为了研究和产业界共同关注的热门话题。 过去十年,NVIDIA通过打造专门针对游戏和图形渲染的GPU,加速了线性代数计算的性能提升。随着深度学习的崛起,NVIDIA又推出了Tensor Cores这种专用硬件单元,极大地加速了AI相关的矩阵乘法操作。
虽然NVIDIA的cuBLAS和cuDNN等深度优化库为CUDA平台带来了出色的矩阵计算体验,但它们大多是预编译的闭源二进制文件,缺乏灵活性和可扩展性,受限于特定硬件平台。相较之下,随着计算平台多元化趋势的显现,需求也逐渐转向支持多种GPU甚至CPU的通用解决方案。 在现实场景中,性能瓶颈逐步从纯计算转向数据移动。尤其是在GPU中,数据从内存到寄存器的传输成本常常超过了算术运算本身。优化数据移动路径,减少不必要的数据复制,成为提升总体性能的关键手段。融合多个计算内核为单一内核执行的方式,能够最大限度地降低内存访问频次,提升吞吐率。
然而,现有大多数预编译矩阵乘法库并未充分支持这种操作,使得针对具体需求定制的高性能内核成为必要。 应对这一挑战,NVIDIA开发了CUTLASS,一个基于C++模板框架的矩阵乘法库,可帮助开发者定制专属的矩阵乘法核。但CUTLASS仅支持NVIDIA GPU,限制了其跨平台推广的可能性。为了实现多硬件、多平台环境下的统一优化,创新团队推出了CubeCL及其矩阵乘法核引擎。这一引擎能够自动搜索并生成适配各种GPU和CPU的优化内核,大幅提升了跨设备的编程效率和性能表现。 CubeCL借助Rust语言强大的类型系统与零运行时开销的特性,将矩阵乘法的复杂流程拆解为四个清晰分层:Tile Matmul、Stage Matmul、Global Matmul和Batch Matmul。
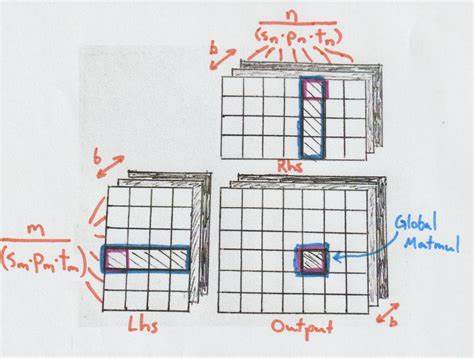
每一层负责不同规模的问题划分与数据调度,实现对数据局部性的充分利用与减少数据传输。通过分治策略的层层递进,矩阵乘法被拆分成更小且更适合硬件特性的子问题,有效地平衡计算资源并提升整体效率。 在最低层的Tile Matmul中,计算核心为一个固定大小的矩形小块矩阵乘法,通常大小为8×8×8或16×16×16。此层直接映射至底层硬件指令,最大限度利用硬件加速单元,如Tensor Cores,通过执行一系列乘加操作完成矩阵小块乘积。值得注意的是,Tile Matmul不仅计算输出,还对累加器寄存器中的结果进行更新,为更大规模计算的累积提供基础。 紧接其上的Stage Matmul负责协调多个Tile Matmul的协同工作,管理共享内存内的数据布局和分配。
通过设计巧妙的分区策略,将矩阵数据划分给不同计算平面进行并行处理。合理使用共享内存能够缓解对全局内存的访问需求,显著缩短数据访问延迟。同时,Stage Matmul支持在加载数据与计算任务之间穿插其他工作,以减少内存等待造成的停顿。 Global Matmul负责跨越更大规模的折叠维度k,反复调入数据至共享内存,并调用Stage Matmul进行部分积累计算。 通过多次迭代,最终合成完整的输出矩阵块。此层实现双缓冲技术,允许加载与计算并行进行,有效隐藏内存访问延迟,提升吞吐率。
为了保证跨平台兼容,Global Matmul以抽象的加载器形式实现从全局内存到共享内存的数据移动。加载策略则根据硬件特性和问题尺寸选择轮询负载或按块切分两种主流方式。 矩阵乘法全局数据划分与派发工作由Batch Matmul完成。它将待计算矩阵划分为若干子矩阵段,调度多个Global Matmul内核并发执行。针对GPU不同的SM(Streaming Multiprocessor)数量和工作方式,Batch Matmul采用多种映射策略,包含行优先、列优先,以及“锯齿形”映射以提高缓存再利用率。通过合理调度,加速各个内核间的数据共享和缓存命中,显著提升整体执行效率。
在具体实现中,矩阵乘法核设计不只是简单套用固定算法,而是需要结合硬件细节做大量权衡。寄存器资源占用占据关键地位,累积器的大小直接影响单个计算任务对寄存器资源的需求,过大可能导致溢存,带来额外开销。双缓冲技术则能有效穿插计算和存储,隐藏延迟,但对寄存器和共享内存的资源需求都较高。如何设计合适的分块尺寸和平衡寄存器 占用与并发性,是优化过程中最严峻的挑战。 多平台矩阵乘法核的另一个重要优化点在于细粒度的计算单位。GPU内部执行单元分为线程(Unit)、线程组(Plane)及线程块(Cube)三级。
优化方案通常以Plane作为最小同步及协作单元,避免线程内部分支带来效率降低,实现指令锁步并行。对数据访问进行内存连续性安排,确保访问模式符合硬件要求,从而实现内存合并(coalesced memory access)和缓存效率最大化。 不同GPU与编程接口对这些执行单元的定义略有不同,CubeCL设计为抽象这些差异,基于Rust的泛型支持,可动态适配CUDA、Vulkan、Metal等多个后端。对于部分不支持Tensor Cores的硬件,则退化为单元级计算,以较小尺寸灵活矩阵块进行基本乘加,从而确保更广泛的适用性。 多平台矩阵乘法核在算法级别也呈现多样化,包含了Simple、Simple Multi Row、Double Buffering等多种方案。Simple方案依赖较低的寄存器压力和重度分割,提高SM并发度;Double Buffering方案通过软件流水线和双缓冲消除内存等待,换取更高的资源消耗和更复杂的内核逻辑。
Specialized和Ordered是针对特定硬件和数据访问模式的高级优化策略,通过加载顺序和任务分配进行细致调控,以兼顾性能和资源占用。 基于这些算法,不同硬件平台呈现出迥异的性能表现。以NVIDIA RTX 4080为例,Simple Multi Row在Vulkan环境下的表现突出,稳定超越官方的cuBLAS和CUTLASS库。换到AMD平台,特别是其基于Vulkan的驱动,Ordered算法则因其对内存利用的高效优化,保持领先优势。Apple M2 Pro在Metal框架下,由于底层对平面执行的控制较弱,部分高级优化受限,性能表现相对逊色但依然具备较好稳定性。总体而言,这些多平台矩阵乘法内核已能够在广泛硬件与编程接口上实现极具竞争力的TFLOPs吞吐量。
在实际应用中,矩阵乘法内核的选择与调优并非一次性任务。矩阵的规模、批量大小以及硬件的具体资源约束均会显著影响最优参数配置。CubeCL团队基于启发式算法动态调整内核参数,尽量避免逐个形状和设备进行耗时全量自动调优。与此同时,社区开放的基准测试平台鼓励用户上传不同设备与算法的性能数据,促进算法自适应性能的优化与完善。 未来,多平台矩阵乘法核的发展方向包括进一步提升异构加速器的互操作性,增强对新兴量化和稀疏计算技术的支持,以及深度融合更多算子实现联合优化。Rust语言和基于类似CubeCL的模块化架构提供了理想的基础,有助于跨平台、跨架构开发情境下的高效自定义。
综上所述,多平台矩阵乘法核不仅仅是算法的迭代,更是软硬件协同、跨平台适配及运行时策略多维融合的产物。在人工智能和高性能计算需求日益增长的浪潮中,矩阵乘法内核的优化将继续扮演推动技术创新和应用进步的重要角色。对研发者而言,理解和掌握这种分层设计及相关优化技巧,是提升计算性能的核心竞争力。随着相关生态的成熟,我们有理由相信,跨设备的高效矩阵计算解决方案将迎来更加广泛的应用和更为深远的影响。