随着人工智能技术的迅猛发展,尤其是大型语言模型(LLM)在多个领域发挥的广泛作用,如何科学有效地评估这些模型成为业界关注的焦点。到了2025年,评估的标准已逐渐远离传统的简单基准测试,更加注重模型在现实场景中是否能够真正为用户提供价值和帮助,打造可用、可靠的智能助手成为新的目标。评估方法的转变与模型能力的进化紧密相关。以往的评估更多关注模型在单一能力上的表现,例如知识问答、数学推理或代码生成的准确率,但这些指标无法全面反映模型在复杂任务中综合运用多项能力的能力。现代智能助手需要在面对模糊指令时灵活应对,合理制定计划,准确调用工具,且能适时调整应对突发状况,同时避免产生错误信息。这样的能力集合意味着评估体系需要具备多层次、多维度的测试方式。
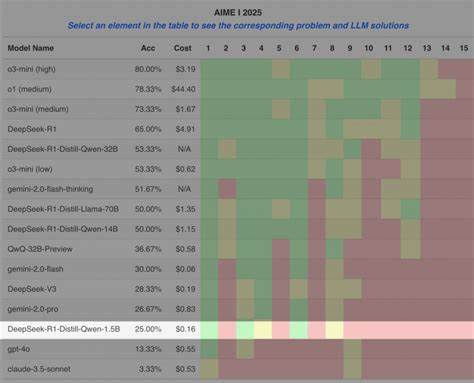
首先是对具体能力的单独测试。知识、推理、数学和编程能力仍然是构建智能助手的基础。例如,知识问答依然借助诸如MMLU-Pro和GPQA这类高质量的数据集进行训练和验证,而数学能力则通过AIME25和MATH-500等竞赛级别的题目来衡量。编程能力评估则借助LiveCodeBench、AiderBench等针对代码编辑和调试的测试集,同时考虑到模型调用外部工具的能力。长上下文管理能力的测试也成为重点,模型需要在长达数万甚至十万令牌的对话或文本中准确检索和利用信息,避免遗忘重要细节。评估工具如NIAH和InfinityBench帮助开发者理解模型对长上下文的掌控水平,并通过多跳推理和多轮共指检查提高模型的上下文理解力。
其次是多能力整合的测试,这部分测试模拟真实环境中的复杂任务,要求模型将推理、工具调用、长上下文管理等综合技能有效结合。GAIA和BrowseComp等真实信息检索类评测通过设定多步查询和检索流程,检验模型的实际问答能力。工具调用则是体现模型智能的重要环节,系统通过TauBench、ToolBench以及稳定版StableToolBench来检测模型调用API完成任务的能力,确保模型不只是产生文本,而是真正实现功能性操作。从更高层面来看,具备适应性和动态调整能力的模型需要在不断变化和不可预知的环境中展现灵活性。游戏化评估在这一方面发挥了巨大作用。ARC-AGI3提供复杂推理和探索任务,TextQuests和Town of Salem等游戏测试模型的长期规划、沟通协作及安全性,从而评估模型在不确定环境下的表现与策略调整能力。
未来预测能力的新兴评测也给能力测定带来了挑战。尽管预测未来存在天然的不确定性,但FutureBench、FutureX提供的基于实时数据的问题,促使模型在多源信息推理的基础上提出合理预测,这类评测帮助理解模型的洞察力和逻辑延伸能力。值得关注的是,评测体系朝着更少依赖主观"模型判定器"(Model Judge),更多引入自动、功能性和客观标准的趋势发展。类似于IFEval检测格式遵循能力的评测,结合严格规范的工具调用正确性检查,避免了由评判偏差带来的误差,提高评测结果的可比性和复现性。与此同时,评测数据集也倾向于覆盖更广泛、实用和易于理解的任务场景,使非专业用户亦可直观感知模型性能的优劣。展望未来,2025年的评估体系不仅关注于模型单点能力的提升,更聚焦于这些能力如何在真实多任务环境中有机配合,确保模型不仅智能,更具备高度实用性。
随着模型规模和复杂度的增加,构建适合实际业务的模型需依托科学多维的评估工具,助力开发者及时发现瓶颈和风险点,不断优化模型表现,实现让用户真正"用得上,用得好"的智能助手。总之,2025年的评估已经超越了单纯的知识储备和推理能力测试,以长远视角兼顾效率、准确度和适应性,强调对工具整合和复杂任务处理的综合考核。未来,人工智能的发展将更趋向于以用户需求为核心,评估体系将在助力模型完善的道路上扮演关键角色,推动智能助手真正走进现实生活,成为人们工作和生活中的得力帮手。 。