Apache DataFusion作为一个高效的开源数据处理引擎,在最近的版本升级中引入了对用户自定义类型和自定义元数据的高级支持,这为数据科学家和开发者带来了极大的便利,也为复杂数据类型和丰富数据上下文的处理铺平了道路。本文将系统性解读DataFusion如何利用Apache Arrow的数据类型体系,通过扩展类型和元数据机制,实现对复杂数据的灵活处理和扩展,探讨其在实际业务及技术场景中的深刻影响。DataFusion的类型系统直接基于Apache Arrow,这种设计策略带来了直观且强大的类型支持。Apache Arrow本身已支持丰富的标量与嵌套数据类型,并且通过零拷贝技术实现了高速数据交换和多语言互操作性,这为DataFusion的稳定性和性能奠定了坚实基础。然而,Arrow的类型系统在逻辑类型与物理类型之间没有明确区分,例如字符串类型就在物理层面体现为Utf8、LargeUtf8、Dictionary(Utf8)等多种形式,而逻辑含义基本一致。为解决这类问题,Arrow引入了扩展类型(extension types)的概念,允许用户定义基于现有物理类型的逻辑类型表示。
这种机制在DataFusion 48.0.0版本得到了充分支持,用户能便捷地利用扩展类型表达复杂的逻辑数据类型,实现针对特定业务需求的个性化数据建模。除了类型自身,元数据(metadata)在DataFusion中扮演关键角色。根据Arrow规范,字段(Field)的元数据是以键-值字符串对的形式存在,这不仅能承载扩展类型的描述信息,还能携带数据使用场景相关的上下文。值得注意的是,之前的DataFusion版本虽然在部分操作如列重命名或选取时保留了字段元数据,但在标量函数、窗口函数或聚合函数的处理中并未全程传递元数据。直到48.0.0版本以后,这一机制得到了全面升级,所有用户自定义函数调用时均可访问完整的输入字段信息并返回带元数据的输出字段,从而极大增强了对复杂数据类型及多样化上下文信息的支持能力。用户自定义函数(User Defined Functions, UDFs)的设计也与元数据机制紧密结合。
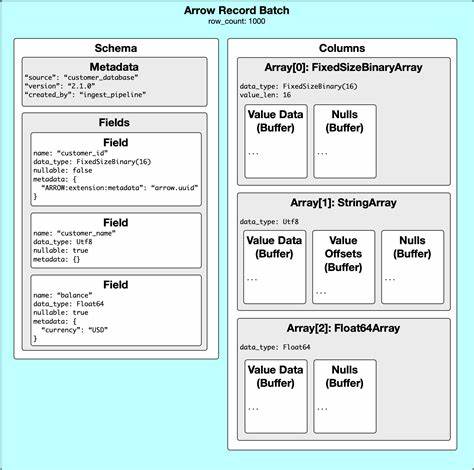
通过在函数规划阶段调用return_field_from_args函数,开发者可以基于输入字段的全部信息,包括数据类型和元数据,生成带有丰富上下文说明的输出字段,从而实现数据验证和灵活的逻辑表达。例如,UUID作为一种典型的扩展类型,就体现了该机制的威力。UUID数据通常以固定长度16字节的二进制形式存储,这在Arrow中对应FixedSizeBinary(16)物理类型,但仅凭物理类型很难判断是否一定为UUID。借助元数据,开发者可以准确判断字段是否是UUID的扩展类型,从而保证函数逻辑的正确性和健壮性。此外,元数据还可用来描述数据编码信息,例如存储图像数据的u8数组的编码格式。若无元数据支持,通常需要额外的编码说明列,导致数据冗余;而有了元数据,就能将编码信息嵌入元数据中,简化数据结构并确保处理方法的正确匹配。
功能调用过程中,UDF不仅能在规划时验证输入元数据,还能在执行时通过invoke_with_args接口访问输入字段的元数据,实现基于上下文动态调整处理逻辑。例如,针对编码格式不同的图像数据,可以根据元数据调用不同的解码函数,实现高效而灵活的运行时决策。扩展类型的引入推动了DataFusion生态的创新和多样化。Rust版Apache Arrow的实现已内置了诸如UUID等标准扩展类型,并为用户提供了try_canonical_extension_type等辅助函数,使其在DataFusion UDF实现中更加便捷。配合实际案例,DataFusion社区开发了三种代表性的UUID相关函数,分别用于版本号提取、字符串与UUID二进制的相互转换,这些扩展极大丰富了数据处理的表现力。上述例子不仅在DataFusion核心中得到体现,还能通过Python绑定库推广到更广泛的数据科学应用,满足不同用户群体需求。
除了扩展类型,元数据的灵活运用还催生了众多创新场景。部分用户利用元数据生成带有上下文信息的输出,直接供数据可视化系统消费,显著提升可视化效果的关联性和准确性。在机器人学等领域,元数据被用来描述空间变换关系,多个坐标系间的转换信息通过元数据传递,使函数能够智能识别和选取相关列,实现复杂的空间数据处理逻辑。这种做法提升了代码的封装性和重用性,降低了应用复杂度。InfluxDB等数据平台则借助字段元数据定义数据模型中的标签、时间戳、字段等逻辑属性,实现了对时序数据的更精准管理和查询优化。这些实战经验表明,元数据为数据管理提供了新的维度,帮助构建更智能化的数据模型与处理流程。
需要注意的是,广泛利用元数据虽然带来便捷,但也存在潜在风险。数据流经过多次转换和过滤操作后,某些元数据可能失效,例如整体统计信息在部分过滤后不再准确。此外,依赖列名进行元数据关联时,一旦列发生重命名或替换,关联关系便可能被破坏。为避免此类问题,建议在设计元数据时采用标识符替代列名,并谨慎评估元数据在数据生命周期中的完整性和有效性。最后,DataFusion元数据和用户自定义类型的新功能得到了业界包括Rerun.io在内企业的积极支持和赞助。该公司在物理人工智能领域的可视化应用体现了元数据技术的强大潜力,推动了相关数据处理能力的不断提升。
总的来看,DataFusion 48.0.0版本在元数据处理和扩展类型支持方面的突破,使得用户能够在数据处理的每个环节更加细致地掌控数据特征和上下文,开拓了数据处理的新领域。无论是增强数据验证能力,实现复杂类型的支持,还是为下游应用提供丰富上下文元信息,DataFusion都展示出其作为现代数据引擎的无限可能。未来,期待社区和用户持续探索元数据和扩展类型的深度应用,打造更加智能、灵活和高效的数据处理生态。 。