随着人工智能技术的不断演进,音频生成领域正迎来一场前所未有的变革。Boson AI团队于2025年推出的Higgs Audio Generation V2(以下简称Higgs Audio V2)不仅实现了技术上的重大飞跃,更以其开源的姿态为开发者和研究者打开了无限可能。作为一款基于大规模预训练的音频基础模型,Higgs Audio V2预先训练于超过一千万小时的多样语音和文本数据,凭借深度的语言理解和声学建模能力,实现了极具表现力和自然感的音频合成效果。Higgs Audio V2的诞生,不仅刷新了业界对声音生成的认知标准,还为多说话人对话、长篇音频生成以及情绪表达等复杂任务提供了突破性的解决方案。首先,Higgs Audio V2在多说话人对话场景表现卓越。过去多说话人音频生成常面临说话人情感和语音能量不匹配的问题,导致对话听起来生硬且缺乏真实感。
Higgs Audio V2通过创新的模型架构和优化算法,使得说话人之间能够协调整体节奏和情感表达,使对话自然流畅,仿佛真人现场对话。该模型支持多语言零样本生成,无需专门针对某一种语言进行后续训练,即可高质量生成多语言多说话人音频,这对全球化的语音应用具有重要意义。此外,长篇音频的生成一直是合成领域的难点,因为音色的稳定性、情感的连贯性和内容的真实感同时要求极高。Higgs Audio V2通过条件提示和上下文控制,实现了长时间段内声音的持续一致和情感表达的动态调整,完全满足有声书、播客等内容领域对长时音频的高品质需求。高保真音频输出是Higgs Audio V2另一大亮点。将采样率从16kHz提升到24kHz显著提升了音质和听感真实度,使生成的声音在高端耳机和扬声器设备上表现更为细腻自然。
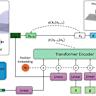
此改进满足了追求极致听觉体验用户的需求,拓宽了音频合成的应用边界。技术架构上,Higgs Audio V2采用了创新的双前馈网络(Dual FFN)结构,能够高效融合文本和音频的多模态信息,从而实现音频语义与声学特征的深度交互。结合专门设计的统一音频分词器,该模型能够捕捉语义和声学双重特征,保证生成音频不仅在语言准确度上领先,还具备卓越的情感和声音细节呈现。训练数据方面,Higgs Audio V2借助Boson AI开发的自动注释流水线,从庞大的音频语料库中筛选并标注了超过一千万小时的音频数据,涵盖各类型声音事件、语音情绪和对话场景。这种丰富多样的数据基础赋予了模型广泛的适应性和强大的泛化能力。在评测方面,Higgs Audio V2在多项权威基准测试中表现优异,特别是在EmergentTTS-Eval的“情绪”和“提问”类别中,分别以75.7%和55.7%的胜率领先于主流对比模型“gpt-4o-mini-tts”。
这一成绩不仅验证了模型在情感表达与语音交互上的领先地位,也展示了其在自然语音合成领域的显著优势。同时,在多说话人对话生成的专门评测中,Higgs Audio V2展现出了较低的词错误率(WER)和更佳的说话人相似度与辨识度指标,明显优于当前部分开源竞争模型,体现了其在复杂语音环境下的强大适配能力。Higgs Audio V2的开源发布沉淀了大量前沿技术,促进了语音合成技术的共享与创新。无论是学术研究者还是开发者,都能够免费使用并基于该模型进行二次开发,推动智能语音应用在对话系统、智能客服、语音助手、有声内容制作等领域的快速落地。值得一提的是,Boson AI团队注重模型推理的资源效率,确保较小规模模型能够在低功耗设备如Jetson Orin Nano上顺畅运行,大规模模型则推荐搭载NVIDIA RTX 4090显卡的环境,有效平衡了性能与硬件需求。这一设计为不同规模的应用场景提供了灵活方案,降低了智能音频技术的门槛。
除了技术性能的突破,Higgs Audio V2还包含丰富的实际应用案例,例如实现了多语种实时对话翻译和语音克隆,展现出高度的实用价值。使用者可以轻松定制不同角色的语音,并让多角色对话听起来自然生动,有效支持游戏、动画配音、虚拟主播等产业的创新需求。展望未来,Higgs Audio V2为音频生成技术树立了新的标杆,其跨模态能力和丰富的语音表现将持续拓展AI与人类沟通的边界。随着模型持续优化和数据持续丰富,预计该技术将在虚拟现实、元宇宙、智能家居等更多领域发挥重要作用,带来更加沉浸式和个性化的交互体验。总的来看,Higgs Audio Generation V2不仅是一款技术先进、性能卓越的音频合成模型,更是一座连接声音与情感的桥梁。它不仅打破了传统语音合成的限制,带来了更加自然、富有情感的语音交流体验,也以开源的姿态促进了产业生态的繁荣发展。
无论是科研探索还是商业创新,Higgs Audio V2都为智能语音未来树立了光辉典范,让人与AI的交流更加轻松、自然与动人。









