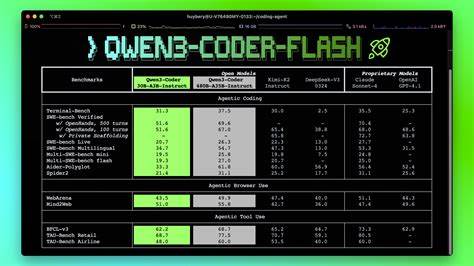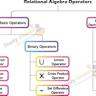
关系代数长期以来被视为数据库理论的数学基础,许多人坚信它源自数学,拥有深厚的数学根基。然而,这种观点往往缺乏具体的阐述和准确的理解。在数据库行业和学术界,"关系代数是数学"这一论断被层层传递,但其中究竟蕴含了什么样的实质意义,值得探讨。关系代数本身到底是不是一个数学概念?它和数学之间的关系又是如何的?本文试图通过细致的分析和真实的历史背景,带你全面揭开关系代数的"数学面纱",分辨事实与误解。关系代数的起源可以追溯到20世纪70年代,由埃德加·F·科德(Edgar F. Codd)提出,作为关系数据库查询语言的理论基础。科德设计的关系代数是一组操作集合,用来对关系(数据库中的表)进行查询和修改操作。
与传统数学上的关系有所不同,科德的关系代数强调有限集合、命名字段,并且致力于易于实现和高效的运算。这种关系代数不是传统数学意义上的抽象代数体系,而是一种工程师设计的编程模型,目的是方便表达查询并能被计算机高效执行。数学中的"关系"则是集合论的重要部分。数学关系一般是无限的,具有严格定义且多用于研究函数、等价关系及偏序等概念。数学中的关系常以"元组"的形式呈现,是基础的数学结构,广泛用于逻辑学和模型理论。数学家阿尔弗雷德·塔尔斯基(Alfred Tarski)曾推广一套基于关系的代数体系,这套体系多用于代数逻辑中,旨在作为第一阶逻辑的无变量表示。
但这种理论较为晦涩,且应用局限,甚至在数学学科内也不是主流研究方向。与科德关系代数相比,塔尔斯基的关系代数更纯粹地服务于理论逻辑,而非直接用于实际数据库设计。实际上,科德的关系代数与塔尔斯基的代数看似有相似之处,但在基础理念、设计目标和使用场景上有显著区别。科德的关系代数为了限制计算资源而设计,强调有限操作和明确表结构,而塔尔斯基则偏重于逻辑的表达和证明体系。现代的关系数据库管理系统(RDBMS)所依赖的查询语言SQL与科德的关系代数也存在许多差异。SQL在实际应用中融入了排序、分组、聚合、视图定义、递归查询、多值逻辑和空值处理等复杂机制,这些内容在原始的关系代数中并不存在。
因此,用"关系代数"来解释SQL的全部行为,显得过于简化和不准确。现代数据库的查询优化过程确实使用类似于关系代数的中间表示,但这些"关系代数"操作集往往经过多次扩展和修改,远非科德最初定义的纯关系代数。用户在SQL中使用的许多函数和语法元素,实际上超出了严谨数学意义上的关系代数范畴。数据库优化器在处理复杂查询时,会将查询拆解成逻辑运算树,这其中就包含了类似关系代数的联合、选择、投影等操作,但它们与数学中严格定义的代数结构有所区别。一个常见误区是认为关系数据库表现出高效性能正因为其拥有数学的强大基础。其实关系代数作为一种理论模型,本身并不能解释数据库的性能优势。
数据库性能更多依赖于索引结构、执行计划、缓存管理及硬件资源等。建立在关系代数模型基础上的查询优化器固然重要,但其背后的实现和优化过程极其复杂,远非简单的数学定理可以直接覆盖。在数学领域中,关系被视为一种通用的数据组织方式,类似于编程语言中的结构体。它们帮助描述实体和实体间的联系,但数学界对此并没有专门发展成完整系统的"关系理论",更不会将关系代数作为数据库设计的切入口。另一方面,一些围绕XML和其他数据模型的查询代数,反而在数学描述上更具形式化和严密性,这反映出现实数据库的多样性与复杂性。对于那些宣称关系代数"基于数学"或"有深厚数学根基"的说法,或许更适合理解为"它基于一种理想化的描述模型"而非"它是纯粹的数学产物"。
这类似于说一个故事是"基于真实事件",带有一定程度的抽象和简化,却不等同于严谨的事实记载。总结来看,关系代数自身更多是工程学的发明,是为解决数据库查询而特制的运算集合,并非严格的数学体系。它不是数学家们用来研究数学对象的工具,也不拥有广泛的数学公理体系支持。它的最大价值在于为关系数据库提供了一个可执行且可优化的查询界面,促成了现代数据库技术的发展。现代关系数据库系统的发展远远超出了单纯关系代数模型,涵盖了排序、递归、空值逻辑、多重集和复杂表达式等,这些内容在纯关系代数中没有体现,也体现了实际应用对理论模型的超越。对于数据库工程师和从业者来说,了解关系代数作为查询中间语言的重要性,有助于理解查询优化和执行。
但期望从关系代数中获得数学上的神秘力量,往往是过高的期待,甚至可能误导对数据库系统技术本质的把握。未来,数据库技术仍将不断发展,新的模型和语言还会涌现,它们可能会结合更多形式化数学工具,也可能会继续沿用成熟的工程经验。无论如何,对关系代数的理解需要回归实际,既不过分神话,也不全盘否定,才能更良好地指导实践,推动技术进步。 。