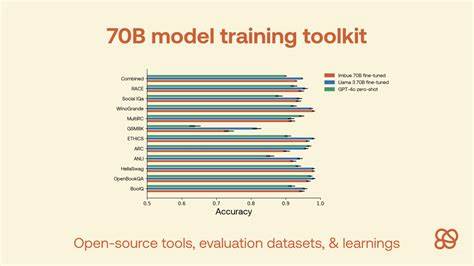
随着人工智能技术的迅猛发展,大型语言模型(LLM)正逐渐成为推动自然语言处理进步的核心力量。近日,韩国著名AI团队Trillion Labs发布了其Tri系列语言模型的最新突破 - - 首个70B(700亿参数)规模的大型语言模型训练中间检查点全面开放,这一举措为全球研究者提供了宝贵数据资源,开启了探索大规模模型训练动态的新纪元。此次公开的Tri-70B模型不仅释放了完整训练过程中的所有关键中间状态,还涵盖了不同规模版本的0.5B、1.9B、7B等模型阶段性检查点,尤其聚焦于韩语、英语及日语的多语言理解与生成能力,为多语种AI研究提供了实证依据。大型语言模型的发展迅猛,而普遍存在的挑战之一便是训练过程的复杂性和难以复现性。大规模模型的训练往往耗时数周甚至数月,消耗巨量计算资源,期间的训练动态和权重变化对于理解模型性能至关重要。过去,由于模型训练检查点的不足,研究人员难以对训练中的学习路径、参数调整和收敛机制进行全方位分析。
Trillion Labs此次发布的Tri-70B模型中间检查点有效解决了该困境,允许外部研究者随时访问约1600亿tokens训练后的各阶段权重状态,配合公开的训练配置、损失曲线和相关文档,完整还原模型训练轨迹。该开放内容中包括了多个训练步骤的数据版本,具体涵盖大约20B tokens对应的0.5B参数版本,40B tokens对应1.9B参数版本,以及160B tokens对应7B与70B参数版本。这递进式的模型规模和数据量划分方式,为研究者提供了极具价值的多尺度分析维度,可以对比不同参数大小下模型的收敛速度、语言理解表现及泛化能力,从而推动算法及架构优化。Tri系列模型不仅在规模上体现出行业前沿水平,更特别关注日韩语言的处理性能。相比现有的国际主流模型,多语言兼容性和本土化语料训练使其在韩语语义理解、日文文本生成方面表现卓越,这对于推动相关区域内智能客服、内容生成、自动翻译等应用都有巨大意义。此外,模型的Apache-2.0开源许可为学术界和企业界提供了宽松的创新环境,在确保知识共享的同时,鼓励商业开发和二次研发。
Tri-70B中间检查点的开放发布也体现了Trillion Labs对AI研究开放透明精神的践行,通过搭建透明可考究的平台,打破了过去因训练成本和数据闭环而导致的研究壁垒。这样的公共资源极大地促进了社区协作,提升了模型复现性,为全球AI学者提供了宝贵的实验材料。技术角度来看,Tri-70B模型采用了最新的Transformer结构优化,结合先进的分布式训练技术和混合精度计算,显著提升了训练效率和稳定性。在训练过程中,模型团队通过严格监控损失函数波动,合理调整学习率以及正则化策略,确保大规模参数的高效收敛。中间检查点的释放让研究者得以观察并分析这些技术细节对模型性能产生的影响,从而为未来更大规模模型的训练提供借鉴。从应用层面看,Tri-70B模型凭借其卓越的语言理解和生成能力,可广泛服务于智能问答系统、文本摘要、对话机器人、内容创作等诸多领域。
其多语种支持优势,特别适合跨境业务和多元文化交流场景,推动企业智能化转型升级。未来,随着AI模型规模持续提升和训练数据愈加丰富,中间检查点机制或将成为行业标配,促进模型训练过程的可解释性和可控性。Trillion Labs的此次开源尝试,不仅为韩语及周边语言的NLP研究注入新动力,也为全球AI社区探索大容量训练数据利用和模型演化机制树立了典范。同时,Tri-70B模型的成功,也体现了东亚地区在人工智能自主创新领域的实力,增强了该地区在全球AI产业链中的话语权。总结来看,首个70B参数级大型语言模型Tri-70B的中间检查点全面开放,标志着语言模型训练研究进入了更具透明度和共享性的新时代。研究者和开发者可以借助这一先进模型资源,深入理解训练过程中的微观变化,推动大模型性能与效率的双重提升。
随着相关数据、代码及文档的持续完善,更多创新性的算法改进和应用探索将得以实现。未来,期待Tri系列及其衍生模型在多语言理解、跨境智能服务及人机交互领域发挥更加关键的作用,为全球AI技术发展注入中国力量,成就智能时代的新篇章。 。