在数据科学与数据分析领域,Pandas作为Python生态中不可或缺的数据处理库,扮演着至关重要的角色。无论是在科研、金融还是人工智能等诸多领域,Pandas几乎是每个分析师和工程师的首选工具。大量公开数据表明,在GitHub上导入第三方包的Notebook中,约有42.3%使用了Pandas。这意味着几乎每两份代码中就有一份依赖Pandas进行数据处理。然而,Pandas作为强大的API,其性能表现却鲜有标准化的评价体系,导致研究人员和开发者难以全面了解不同Pandas优化方案的效果与适用范围。正是在这样的背景下,PandasBench应运而生,成为首个针对Pandas API的专门基准测试平台,专注于单机环境下的真实应用场景。
PandasBench由研究团队精心构建,囊括了102份来自Kaggle的真实Notebook,总计3721个代码单元(cell),涵盖了Pandas API在现实工作流程中的广泛使用情况。其采集方法严格遵守真实世界覆盖性原则,不仅保证了代码的真实性,还确保了代码可执行及数据的多样性和丰富性,从而真实反映用户日常使用Pandas的情境。传统的Pandas性能评测多依赖于人工合成数据或简单基准场景,难以还原复杂多变的实际需求,而PandasBench的出现恰恰弥补了这一空白。 PandasBench的设计理念极富创新性。它不仅仅针对Pandas API的核心功能,还特别强调了数据清洗、文件读写、即时结果观测等在实际分析中必不可少的环节。此外,PandasBench创新地采用了非统一数据规模调整策略。
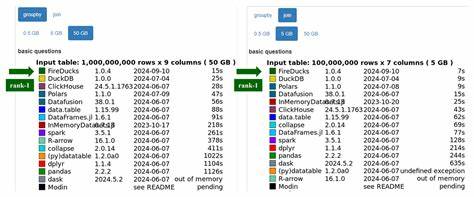
换句话说,每个Notebook的数据规模单独按需缩放,以实现预期的运行时间,如大约5秒,这种以运行时长为基准的调整方法,更有效地模拟了各类真实负载,避免了以统一倍数缩放导致的应用不匹配问题。 在充分准备和清理Notebook代码的基础上,PandasBench团队还针对环境依赖进行了细致修正,比如替换废弃API,调整库版本等,确保所有测试均在可控环境下顺利运行。这一细节上的精准打磨不仅保证了基准测试的严谨性,更提升了对不同Pandas替代和补充实现方案的兼容性评测能力。 借助PandasBench,研究人员系统评估了包括Modin、Dask、Koalas等流行Pandas API替代方案以及Dias这一补充工具。这些工具的目标均旨在通过增强并行计算或改进内存管理来提升Pandas性能。然而,基于PandasBench的测试结果揭示出令人深思的现实:绝大多数情况下,这些系统并未带来显著的速度提升,反而经常引发高内存消耗甚至执行失败。
诸如Modin在单机环境下的内存占用可达上百GB,使得普通设备几乎无法承载测试,Dask和Koalas也面临覆盖率不足且运行不稳定等问题。 Dias虽然表现相对优异,但仍未实现对所有场景的加速支持。如此局面凸显出当前Pandas性能优化生态的瓶颈,也彰显了PandasBench作为评测和改进工具的不可替代价值。 在深入分析基准测试过程中,研究团队惊讶地发现数据规模的调整对执行结果有着非常显著的影响。以Koalas为例,随着数据量的增加,因其依赖的JVM环境内存限制,失败率明显攀升。Modin和Dask也表现出因类型推断不准确或数据转换机制不完善而导致的异常。
这一发现不仅警示开发者需要关注规模适配问题,还体现了基于真实负载的Benchmark对于揭露隐藏缺陷的巨大贡献。 PandasBench的出现不仅为开发者和研究者提供了系统性评测工具,也为优化Pandas生态链注入了信心和动力。通过明确现有技术的不足,PandasBench引导社区聚焦于内存高效管理、API覆盖率扩展及并行执行策略的创新。尽管目前PandasBench主要针对单机负载,未来随着数据量爆炸,分布式与云端处理场景也将成为其扩展重点,为整个Python数据分析生态带来更为科学和专业的性能参考。 在机器学习和数据分析场景日益普及的今天,PandasBench将成为衡量技术进步的重要标杆,激励更多优秀的工具和库被创建和完善,从而推动数据科学技术走向更高效、更易用的新时代。正如研究团队所言,PandasBench不是终点,而是迈向全面、系统Pandas性能优化的坚实起点。
总结来看,PandasBench基于真实、可执行且多样化的单机Pandas代码环境,创新性地提出运行时长为目标的数据规模缩放方法,系统评测了多个流行Pandas替代和补充技术,揭示了当前生态的应用瓶颈及未来改进方向,具有重要的行业指导和研究价值。希望随着社区的共同努力,PandasBench能够持续演进,成为推动Pandas及其相关技术持续优化的重要助力,助力中国乃至全球的数据科学家从容应对日益复杂多变的数据挑战。