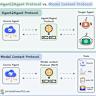
随着数据处理需求的不断增长,寻找高效且灵活的数据查询方案成为许多开发者关注的重点。Scheme-dql作为一款基于S表达式的数据查询语言模块,因其简洁灵活的语法和与Scheme语言环境的高度融合,正逐渐受到程序员的青睐。本文将深入探讨Scheme-dql的设计背景、核心原理以及实际应用,并分析其在Guile环境中的优势,帮助开发者更好地理解并运用这一工具。 Scheme-dql的诞生源于对更自然、结构化的数据查询语言的需求。传统的数据库查询语言如SQL,在处理结构化文本数据或嵌套数据时,常常显得不够直观。而Scheme-dql采用S表达式作为数据结构和查询表达的基础,使得表达复杂数据关系变得更加简洁和易读。
S表达式以其括号嵌套结构,天然适合描述树形或递归嵌套的数据格式,这对于需要解析复杂数据结构的场景而言极具优势。 作为Scheme语言体系中的一员,Scheme-dql在语法和数据结构上与Guile的天然兼容,这意味着开发者可以直接利用Guile的特性来扩展和集成查询功能。Guile作为GNU项目的官方脚本语言,提供了强大的宏系统和灵活的函数式编程支持,使得Scheme-dql不仅能执行静态查询,还能够进行动态生成和组合查询操作,提高了数据处理的灵活性和可维护性。 在实际应用中,Scheme-dql展示了对S表达式数据的高效解析能力。许多配置文件、代码生成脚本和复杂的数据交换格式本身就是以S表达式或者类似嵌套结构存在,通过Scheme-dql,开发者可以用简洁的查询语句快速抽取目标数据。这不仅提高了开发效率,也降低了出错风险。
例如,在代码分析或meta编程领域,通过Scheme-dql可以方便地提取函数定义、注释或依赖关系,为自动化工具和分析平台提供支持。 此外,Scheme-dql作为Proof of Concept的项目,体现了其设计者对语言简洁性的追求。它并非一个重型的数据库查询引擎,而是一个轻量级、具备可扩展性的模块,专注于满足脚本级别或中小规模数据处理的需求。轻量意味着更低的依赖和更快的启动时间,这对于嵌入式脚本或动态配置环境尤为重要。开发者可以根据具体需求,灵活调整和改进模块,甚至将其作为构建更复杂数据查询系统的基础。 再谈到Scheme-dql的语法和查询机制,其核心思想是利用S表达式表达查询模式与数据匹配,通过模式匹配和递归遍历实现精确的信息提取。
这种方法区别于常规关系型数据库的表结构和SQL语法,更加贴合Lisp/Scheme的编程哲学,即代码与数据同构,表达式本身既是数据又是程序。通过Scheme-dql,开发者不仅能够查询数据,更能在查询中嵌入函数调用和逻辑判断,从而实现高度动态和自定义的查询流程。 此外,Scheme-dql的开源特性为社区发展提供了良好的基础。任何对符号处理、宏扩展或领域专用语言设计感兴趣的程序员,都可以深入其代码库,学习其实现思路,或者贡献新功能。随着开源生态不断壮大,Scheme-dql有望在更多实际项目中得到验证和优化,也为Scheme语言在现代数据处理领域的应用开辟了新路径。 针对未来发展,Scheme-dql可以进一步结合现代大数据处理技术,引入并行查询、多线程执行及网络分布式支持等功能,从而扩大其适用范围。
同时,通过与其他数据格式如JSON、XML的互操作,也能实现更广泛的数据集成。此外,增强用户友好性的交互界面和文档体系,将有助于更多初学者快速上手,加速社区的普及和推广。 总而言之,Scheme-dql作为一种基于S表达式的数据查询语言模块,凭借其独特的设计理念和灵活扩展性,为Guile和Scheme用户提供了一种高效、简洁的数据查询工具。它不仅满足了结构化数据解析的需求,也在函数式编程语境中展示了强大潜力。随着更多应用场景的出现和持续的社区投入,Scheme-dql有望成为数据处理领域的重要组成部分,推动Scheme语言生态更上一层楼。对于开发者而言,掌握Scheme-dql不仅能提升数据操作能力,更能开启一扇通向函数式表达式世界的大门。
。