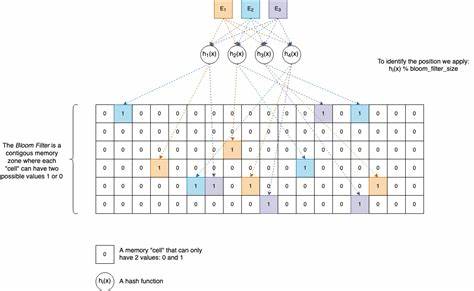
布隆过滤器(Bloom Filter)作为一种高效的概率型数据结构,自1970年由计算机科学家伯顿·霍华德·布隆(Burton Howard Bloom)提出以来,因其在节省空间和快速查询方面的独特优势,逐渐应用于多个计算领域。随着数据量的快速增长,传统的数据结构如哈希表等在内存和速度上的不足愈发明显,而布隆过滤器以其轻巧的存储需求和高效的查询性能,成为字典过滤、黑名单管理、缓存优化等场景中的优选方案。在C语言环境下实现布隆过滤器,展现了编程中的空间和性能优化智慧。理解布隆过滤器的核心机制,需要先了解它如何完成对集合元素存在性的检测。布隆过滤器通过一组哈希函数,将输入元素映射到位数组中的若干个位置,将对应的位设为1。查询时,对同一元素同样进行哈希运算,检查对应位置的位是否全为1。
如果任意一位为0,可以确定元素不在集合中;如果所有位均为1,则元素极有可能存在,但也存在一定的误判概率。这种“半确定性”使得布隆过滤器比传统集合结构占用更少的空间,但换来了可能的假阳性。关键在于合理配置哈希函数数量和位数组大小,以平衡误判率和内存占用。实现布隆过滤器的基础是对底层位数组的高效操作。C语言本身不支持单个位存储,因此通常通过用uint32_t类型数组模拟位向量来管理。每个uint32_t变量包含32个位,通过位操作完成对单个位的读取和设置。
实现时,需要计算目标位所在的数组块位置和位偏移,利用位运算完成高效的读写操作。确保越界检测,避免非法访问,提升代码稳定性。哈希函数选择是布隆过滤器效果的核心。C语言实现中常采用简单而高效的哈希算法,比如djb2和sdbm。这两种算法设计简洁,执行速度快,且能够较好地分散元素哈希值,在非安全敏感环境下表现良好。为了实现多个哈希函数,可通过不同的种子值或者从少数哈希函数衍生出多种哈希结果,避免计算开销过大。
布隆过滤器的数据结构设计中,除了位向量,还需要维护哈希函数指针数组以及记录哈希函数数量和已添加元素数目等信息。创建时通过动态分配管理内存,保证灵活性,也方便销毁时释放资源。函数接口设计应涵盖初始化、销毁、添加元素及检测元素等操作,支持通用数据输入以及字符串简化接口,提升使用便捷性。在实际使用中,布隆过滤器拥有极佳的性能和空间优势。它广泛应用于大型数据库查询优化,用于快速排除不存在的数据请求,减少磁盘或网络访问带来的开销。在黑名单过滤、缓存同步、网页爬虫去重等业务场景,布隆过滤器均可显著提升系统效率。
针对C语言实现,代码结构简洁且易于理解,上手相对容易。开发者可基于此进行扩展,如增加多线程安全支持、结合更先进的哈希算法提升准确度,或结合其他数据结构实现复杂功能。虽然布隆过滤器不能复原元素且带有假阳性风险,但合理调参使其误判率低至可忽略水平,完全满足非安全关键系统的需求。对初学者而言,布隆过滤器的实现过程涉及基础的数据结构设计、指针和内存管理、位运算技巧及哈希函数运用,是不可多得的学习实践机会。近年来,有研究提出更先进的替代方案如库谷过滤器(Cuckoo Filter),在某些方面进一步提升布隆过滤器的功能与性能,但布隆过滤器依然以其简洁和高效备受推崇。对于编程人员来说,掌握C语言下布隆过滤器的实战实现,不仅丰富了算法与数据结构技能,也为应对大数据时代的挑战奠定工具基础。
通过动态内存管理、位操作和函数指针的结合,布隆过滤器代码展现了C语言在资源有限环境下的强大适配能力,堪称效率与简洁的典范。布隆过滤器的设计理念也启示我们在面对庞大集合数据时,不必拘泥于传统完全准确的存储方式,而是可以通过概率手段和算法优化实现空间时间的最佳平衡。总之,在理解数据结构原理和精通底层语言操作的基础上,C语言布隆过滤器实现为开发者提供了极具实践意义的学习案例,值得深入研究和应用推广。