随着人工智能、大数据和高性能计算的快速发展,矩阵乘法作为基础计算在多种应用中扮演着核心角色。AMD最新发布的RDNA 4架构GPU搭载了第三代矩阵核心,显著提升了通用矩阵乘法(GEMM)操作的性能表现,为开发者提供了更强大的计算工具。本文将深入解析RDNA 4架构中矩阵核心的设计革新,介绍如何利用这些核心高效执行矩阵运算,并通过示例代码演示其应用,助力开发者在实际项目中充分发挥AMD显卡的计算潜力。AMD RDNA 4架构矩阵核心的性能提升基于其对16x16矩阵乘加操作的优化。相比上一代RDNA 3,RDNA 4在浮点运算能力上实现了翻倍提升,支持FP16和BF16格式达到每计算单元每时钟1024浮点操作,整合了更多指令支持和更简化的通用寄存器布局,极大降低了寄存器压力,提升了执行效率。具体来看,RDNA 4新增的WMMA(Wave Matrix Multiply Accumulate)内置函数承担了矩阵乘加操作的核心职责,这些指令具备更简洁的参数结构,不再兼容RDNA 3的寄存器布局,需要开发者使用针对RDNA 4定制的新接口。
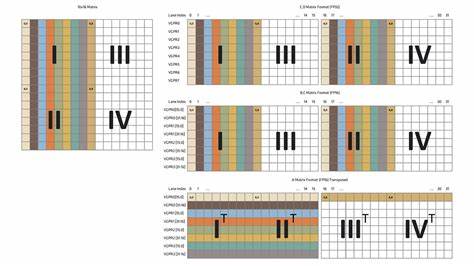
矩阵乘法形式统一为D=AB+C,其中矩阵A、B是乘数,C是中间矩阵,D为结果矩阵。WMMA内置函数只能处理16x16维度的矩阵,因此当矩阵尺寸不满16时需进行填充,超出部分则通过拆分为多个16x16子矩阵分别计算,从而兼容更大规模的矩阵乘法需求。RDNA 4架构的WMMA操作引入创新的向量通用寄存器(VGPR)分配方式,将一个完整16x16矩阵的数据拆分成各个线程负责部分元素的方式存储,每个波前中的32个线程分别负责加载和计算8个矩阵元素,避免重复加载数据,节约寄存器资源,提升执行效率。此外,针对矩阵存储格式,B、C、D矩阵采用行优先存储,而A矩阵为转置形式的列优先存储,这种设计合理分配了数据读取和计算负载。RDNA 4的WMMA内置函数拥有诸多变体,开发者可根据数据类型灵活调用。最常用的是支持16位浮点数乘法,32位浮点数累加的版本,即__builtin_amdgcn_wmma_f32_16x16x16_f16_w32_gfx12。
使用时,需注意该函数要求所有波前线程协同操作而非单线程计算,体现了并行计算的高效思路。为了优化32位浮点数转16位浮点数的载入过程,RDNA 4还提供了设备内置函数__builtin_amdgcn_cvt_pkrtz,可将两个32位浮点数转换并打包成一个32位向量寄存器,优化数据传输和寄存器占用,提升编译器生成的代码效率。开发者在编写HIP内核时,可以利用这种类型转换函数将输入矩阵快速转换并载入GPU寄存器,随后直接调用WMMA内置函数进行计算,大大简化了矩阵乘法的编程复杂度。相比RDNA 3,RDNA 4的寄存器布局更为简洁。过去在RDNA 3中,为了支持矩阵乘法需要多线程间复杂的数据同步和数据重排,这在代码设计与性能调优上带来额外负担。RDNA 4则省略了这些复杂步骤,矩阵D和B均采用高度一致的布局,减少了线程间通信,提高了指令执行的流水线效率。
利用这些改进,开发者可以方便地链式调用多个WMMA指令,完成复杂神经网络推理的计算任务。例如,在多层感知机(MLP)的实现过程中,输入层通过矩阵乘法产生中间激活值,中间激活值继续与下一层权重矩阵计算,最后产生输出层结果。RDNA 4的WMMA内置函数让这种串联计算变得高效且简单,示例代码展示了如何载入权重矩阵和输入数据,并连续调用两个WMMA指令完成两层感知机的推理计算。开发者无需在数据布局上进行额外的线程通信控制,降低了代码复杂度。实际应用中,虽然示例主要演示16大小矩阵的乘法,但更大尺寸的矩阵计算通过矩阵拆分也能充分利用RDNA 4矩阵核心的性能,适应不同规模的深度学习和图形计算需求。值得一提的是,AMD为RDNA 4矩阵核心开发了丰富的软件工具链支持,包括HIP编程模型拓展和Orochi库的动态API切换能力,方便开发者将现有CUDA或HIP程序迁移并高效运行于AMD显卡平台。
整体而言,AMD RDNA 4架构的第三代矩阵核心通过提升每计算单元的浮点吞吐量、优化寄存器分配和简化波前内核同步,极大增强了矩阵运算的执行效率。配合专门设计的WMMA内置函数和数据类型转换函数,开发者能够以更简洁的代码实现高性能的矩阵乘加计算,助力人工智能推理、图形渲染和科学计算等领域的性能突破。未来随着硬件和软件生态的进一步完善,AMD RDNA 4架构有望成为GPU加速计算的新标杆,为开发者带来更广阔的创新空间和更优异的性能表现。总之,深入掌握RDNA 4矩阵核心的使用方法及其性能优势,将显著提升基于AMD平台的GPU计算效率,助力加速AI模型训练和推理、复杂图形处理任务的实现。推荐开发者结合AMD最新ISA参考指南,积极探索和优化矩阵核心相关代码,充分发挥RDNA 4在浮点矩阵计算方面的竞争力。