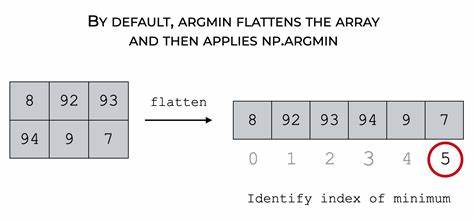
在现代计算任务中,大数据处理和数值计算需求日益增长,如何在庞大的数据集合中快速找到最小值索引(即argmin)成为了性能优化的关键环节之一。尤其是在涉及浮点数的计算场景里,由于浮点数的特殊性质和比较机制,实现高速且准确的argmin操作带来了独特的挑战。本文深入探讨了在Rust语言环境下,针对一组已知全部为非负浮点数(包含正数和零,且不包含无穷大及NaN)的动态数组,如何设计和优化argmin函数,以获得显著的性能提升。传统的浮点数最小值索引寻找方法往往依赖于标准库的排序和比较接口。例如,在Rust中,常见做法是通过迭代器结合total_cmp函数进行元素比较,确保对所有浮点数(包括特殊值)得到正确排序,但这类方法虽然严谨,性能却受限于复杂的比较逻辑。针对百万级别数据,此类实现的运行时间通常在五百微秒上下,这在一些追求极致速度的应用中仍显不足。
为突破这种性能瓶颈,可以基于所知数据前提进行定制化优化。首先可以尝试使用Rust中提供的部分比较(partial_cmp)函数,搭配unwrap_or以防止理应不存在的异常比较失败。此举避免了完全排序的复杂判断,略微减少比较开销,使得处理速度相较于普通total_cmp有所提升,但仍未达到最优。进一步优化思路源自于浮点数在计算机内存中的存储方式。IEEE 754标准定义了浮点数的二进制表现形式,特别是对于非负浮点数而言,将浮点数视为同等大小的无符号整数(u32)在数值排序上是等价的。这意味着对于全部非负的数据集合,可以直接通过其底层位模式进行比较,极大简化了比较过程。
这样的策略不仅避免了复杂的浮点比较逻辑,还能利用整数比较的高效性和硬件层面的加速,使得argmin的计算速度大幅度提升。基于此原理,通过Rust的to_bits方法获取浮点数对应的二进制位,再以此为键进行最小值索引搜索,可以实现约三成的性能优势,相较传统方法在百万级数据测试中将执行时间从五百微秒优化至三百七十微秒左右。实现这一方法的关键在于确保先验条件 - - 数据中不含负数、无穷大和NaN值。一旦这些条件被破坏,基于二进制位的排序可能引发错误结果。此外,为了验证不同方法的性能表现,可以基于Rust的criterion库构建全面的基准测试。通过生成特定模式的测试数据,来比较传统total_cmp、简单reduce迭代、partial_cmp及u32 bit key比较的执行速度,可获得实证数据支撑优化策略的合理性。
基准测试结果清晰表明,利用浮点数正值的位级排序方法远超其他方案的性能,体现了理解底层数据结构与语义间桥梁的重要性。除了理论解析和性能测试,实际上在许多科学计算、图像处理、金融建模及机器学习领域,快速准确地获得数组中最小元素的索引对于算法效率至关重要。采用此类优化策略能显著减少整体计算耗时,提升系统响应速度。需要特别注意的是,虽然单纯从性能角度进行改写表达了优势,但在实际工程环境中仍应根据数据的完整性和容错需求来评估应用范围。比如存在负数、NaN或者不确定值的情况时,应依旧采用安全完整的比较方案,防止因优化而带来错误结果。综上所述,通过对浮点数存储机制的深入理解,结合Rust语言灵活的迭代和比较接口,可以设计出针对特定场景高效求解浮点数最小值索引的方案。
基于to_bits转换后的整数键进行argmin,是一种简单却极具性能优势的实现方式。在未来大规模数值计算需求日益增长的趋势下,这类底层优化手段将为应用性能提供坚实的技术支撑,值得进一步探索和推广。对于开发者而言,理解算法背后的数据结构本质、利用语言特性和硬件特点,始终是提升代码运行效率的不二法门。 。