在当今科学研究飞速发展的时代,科学文献数量呈现指数级增长,研究人员想要紧跟领域内最新动态变得愈加困难。面对海量信息,如何快速准确地获取关键知识,已经成为亟待解决的问题。近年来,基础模型,尤其是大语言模型(LLM),因其强大的自然语言处理能力,逐步被引入科学文献筛选、信息提取和知识综合等任务,但评估各模型在科学任务中的具体表现依然充满挑战。 传统的评测基准往往静态且规模有限,难以满足科学领域任务的复杂多变性,其评估结果难以反映最新模型的实际能力。为应对这一困境,SciArena作为一款开放且协作性极强的平台应运而生,专注于科学文献任务中基础模型的性能比较与评估。平台创新地采用社区众包机制,让科研人员直接参与模型输出的对比和评价,结合人类专家的主观判断,弥补了自动化评测指标的局限性。
SciArena的核心优势在于聚焦科学领域特殊的知识需求,将复杂的科学查询与精准文本检索相结合。平台依托Allen Institute for AI开发的多阶段检索管道,涵盖查询拆解、文段检索与重排等环节,确保为每个问题调取到高质量且相关的文献片段。随后,这些检索到的背景内容连同用户提出的问题一起输入给两个随机抽取的基础模型,模型以长文本形式输出涵盖详尽论证和引用的回答,这保证了答案既具备科学依据又体现语言模型的生成能力。 在模型响应生成后,SciArena通过统一格式标准化文本和引用样式,去除潜在的风格差异,从而避免评判受到形式因素影响。社区科研人员在平台上以盲评形式参与对比投票,选出更符合信息需求的答案。这种设计不仅提升了评估的公平性和客观性,还保证了数据的高可信度。
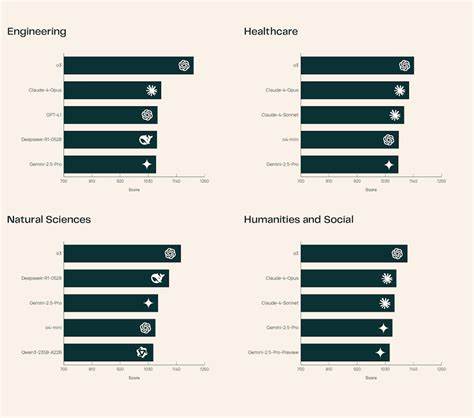
截止2025年6月底,已有来自众多领域的102位资深研究者累计投票超过13000次,为模型排名提供了坚实的数据基础。 截至目前,SciArena已集成23款具备代表性的最前沿基础模型,涵盖医学、工程、自然科学等多个学科。其中,名为o3的模型以在不同科学领域的均衡表现位居榜首,其回答不仅技术细节丰富,尤其在工程学领域展现出深入的专业性。其他模型则在各自优势领域表现突出,如Claude-4-Opus在医疗健康领域表现优异,DeepSeek-R1-0528在自然科学领域也获得高度评价。这种细致区分和多维度评价模式,为模型开发者提供了针对性的改进方向。 SciArena还推出了SciArena-Eval元评测工具,基于收集的人类偏好数据,衡量自动化模型评估系统预测人类选择的准确率。
值得注意的是,尽管顶尖模型o3在预测准确率上达到了65.1%,这一水平仍明显低于通用领域如AlpacaEval和WildChat中超过70%的准确率,反映出现有自动化评测方法在科学推理和复杂信息理解任务中的短板。该发现引发了业界对打造更健壮评测技术的迫切需求,也为后续研究指明了方向。 SciArena不仅在平台功能上不断完善,更重视数据质量管理。所有参与评分的专家需具备至少两篇同行评议出版物背景,并接受统一培训以保证评判标准的一致性。平台采用盲评机制,并通过加权Cohen’s κ统计指标评估评审者之间的一致性和个体自洽性,结果分别达到0.76和0.91,体现了高度的评价规范和数据可靠性。这种严谨的数据治理为模型性能评价树立了高标准范例。
目前,SciArena仍在持续扩展其模型库,并希望与更多模型开发团队合作,引入更多新兴基础模型以适应不断变化的科研需求。此外,未来将评估和优化构成检索增强生成(RAG)管线的各个环节,如文献索引构建和提示词设计,进一步推动平台评估体系的整体精度和适用性。 对于科研社区而言,SciArena不仅是一个技术评测工具,更是一个促进交流、汇聚智慧的平台。研究者可以通过参与投票、追踪排行榜实时动态来深入了解不同基础模型的优劣势,指导自身研究及AI辅助工具的选择。模型开发者也能根据反馈数据快速迭代,推动技术进步。随着平台功能不断丰富,预计SciArena将在科学知识发现和传播的未来中扮演更加关键的角色。
总之,SciArena通过结合社区力量、前沿技术和严谨方法,为科学文献领域的大语言模型评估提供了创新范式。它有效弥补了传统基准的不足,促进了模型性能的透明、公平和动态监测。面对快速演进的AI基础模型生态,SciArena为科学研究者和技术开发者搭建了可信赖的桥梁,助力科学知识更高效、更精准地传播与应用。未来,随着更多模型和评估维度的引入,SciArena有望成为科学智能时代不可或缺的重要资源,推动科研创新迈入新的高度。