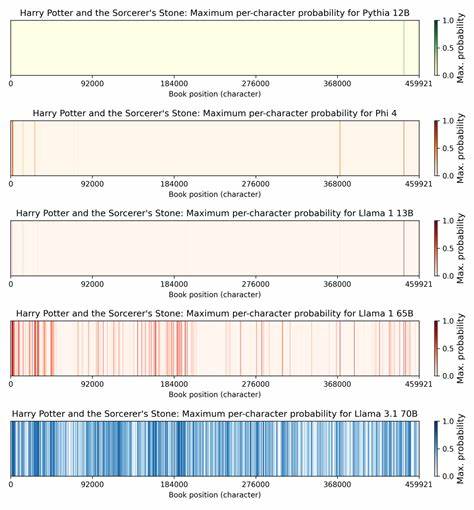
近年来,随着人工智能技术的迅猛发展,尤其是大型语言模型(LLM)的兴起,围绕其训练数据来源和版权问题的争议日益激烈。人工智能模型是否会复制训练中涉及的受版权保护的作品,成为法律界和技术界共同面临的核心问题。Meta公司研发的Llama 3.1 70B人工智能模型最新研究显示,该模型能够准确复现《哈利·波特与魔法石》一书中近42%的50词段落,这一发现不仅震惊业界,也对未来的版权诉讼提出了新的挑战。来自斯坦福大学、康奈尔大学和西弗吉尼亚大学的多学科研究团队采用严谨的概率计算方法,评估了包括Meta、微软及EleutherAI等多家机构公开权重模型在内的生成文本能力。研究通过逐段拆分书本内容,从前半部分的50个词开始,计算模型在后续50个词准确复现的概率,定义高于50%的概率为“记忆”。他们发现,与去年发布的Llama 1 65B模型相比,Llama 3.1 70B版本在训练中或数据处理方面存在明显增强的“记忆”能力,尤其是对于《哈利·波特》和《1984》等广为流传且引用频繁的作品表现突出。
这种现象也引发了对Meta训练过程的深刻反思。训练过程的庞大数据量和持续迭代模式,极有可能导致模型对训练资料的过度拟合,甚至无意中“抄袭”原文段落。此类现象不仅影响模型在内容生成的原创性,也直接关系到版权法中的“衍生作品”概念,及判定使用是否构成侵权的关键因素。Meta是否为了追求模型的语言理解和生成准确性,放松了对训练内容去重和模糊化的要求?这种模式是否在无意间加剧法律风险?至今尚未得到官方明确回应。然而,该研究也揭示了一个不容忽视的事实:记忆现象在不同书籍间差异悬殊。例如,知名畅销书和文化标杆作品易被模型广泛“记住”,而一些较冷门或引用较少的作品,其复制比例极低,这对版权诉讼中“集体诉讼”模式的适用提出了复杂质疑。
法律专家指出,要在法庭上成功确立集体侵权责任,需要证明所有受影响作者处于相似的法律和事实环境。显著的记忆差异无疑使此类集体诉讼面临更大挑战。AI训练过程是否本身算是对版权内容的复制,亦是争论焦点。部分法学观点认为,训练即复制,无论模型输出如何,都构成侵权;而另一部分则强调输出结果的原创性和变革性,主张这属于合理使用范畴。Meta的Llama 3.1 70B大量复制《哈利·波特》文本的能力,可能让法庭对其合理使用辩护持更谨慎态度。在合理使用的判定中,是否具有“转化性”——即创造出明显不同的新内容,是关键因素之一。
模型能够一字不差生成大量原文,使得转化性的论点被削弱。此外,Google的类似诉讼胜诉经验部分基于其系统在回应查询时限制文本的长度,避免输出长篇原文,而Llama模型的表现则显著不同。与此同时,不同模型的“开放权重”与“闭源模型”之间的法律风险也有别。开放模型因研究者可以直接访问内部概率和权重参数,更容易被检测记忆内容;闭源模型则通过接口过滤减少敏感内容生成,或许能缓解一定法律压力。这种现象反映了技术透明度与法律风险之间的复杂权衡。对于创作者和版权持有者而言,这一发现无疑是保护自身权益的有力依据,也为未来版权诉讼提供了新的实证支持;对AI开发者而言,则敲响了警钟,技术创新同时必须兼顾法律合规和伦理规范。
迈向未来,监管机构与产业界需要更精细地界定数据训练的合法边界,制定更加合理和灵活的版权政策,兼顾技术进步与权利保护。或许,技术手段的革新也能协助缓解这一难题,比如通过开发更先进的去重与模糊化算法,限制模型对特定文本的过度记忆,提升生成内容的原创度。同时,推动法律体系与司法解释的创新,确保公正有效地应对人工智能引发的版权挑战。总而言之,Meta AI模型对《哈利·波特》原著近半内容的复制现象,揭示了当前AI训练与应用中的版权复杂性,也呼唤技术与法律的双重进步。只有在科研与法律的共同努力下,才能为人工智能的健康发展奠定坚实基础,促进创新与版权保护的和谐共存。









