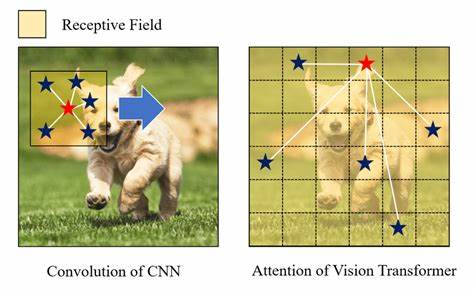
随着人工智能和计算机视觉技术的迅猛发展,视觉变换器(ViTs)与卷积神经网络(CNNs)成为两大主流架构,推动了图像识别、目标检测、语义分割等任务的进步。传统观点认为,由于视觉变换器采用的自注意力机制存在二次方计算复杂度,其在高分辨率图像处理时会遇到性能瓶颈和内存消耗激增的问题。但最新研究及实测数据表明,这种批评存在偏差,ViTs在分辨率提升至至少1024×1024像素时依然表现出良好的扩展性,且在许多情况下速度甚至优于等量级的CNN模型。 从体系结构的角度来看,CNN通过局部卷积核滑动捕捉图像信息,逐级构建特征地图,通常输出相对较低分辨率的特征以完成后续任务。这种方法有效抓取局部特征,且在多年发展中经过优化,拥有成熟的加速工具和硬件支持。相比之下,ViTs先将输入图像分割为若干个固定大小的非重叠图像块,然后对所有图像块的特征执行多层全局自注意力运算。
这种设计不仅能够高效捕捉长距离依赖,还使得模型结构更加简洁。然而,由于自注意力计算资源随着输入规模呈二次增长,外界普遍担心ViTs在处理高分辨率图像时速度和显存消耗将呈爆炸式增加。 针对这一质疑,刘克斯·贝耶等专家使用PyTorch框架,借助torch.compile技术以及tim库中的多种主流ViT和CNN模型,进行了多设备、不同批次大小和数据类型下的综合基准测试。测试涵盖了包括NVIDIA GTX3070等流行GPU,观察了模型的推理速度、浮点运算次数(FLOPs)和峰值显存使用情况。测试结果展现了ViTs出乎意料的强劲表现,不仅在多数测试条件下能够稳定运行至1024×1024像素分辨率,大多数情况下速度优于等效规模的卷积网络。 这一现象的背后原因多方面。
首先,FLOPs并不总是能直接反映推理速度,硬件架构和深度学习库优化对模型执行效率有着决定性影响。其次,在某些现代GPU中,ViT自注意力机制的优化实现(如局部自注意力机制和特定的矩阵乘法高效算法)极大地减少了计算瓶颈。最后,ViT的架构简洁减少了中间临时变量的存储需求,使其在显存利用率上通常更为节省,尤其是在中高分辨率输入下,能够顺利执行而不至于显存溢出。 数据的固有特性同样决定了对图像分辨率的需求不能一味追求极致。研究指出,对于绝大多数自然照片,分辨率224×224像素足已提取充分信息完成分类等任务;对于含有文本的照片、手机屏幕截图或图表,448×448像素的分辨率通常已足够;涉及桌面屏幕截图或单页文档的复杂场景时,分辨率接近896×896像素即可满足需求。高分辨率图像大多只是满足人类对视觉细节和美感的要求,而在计算机视觉模型中,这些超高分辨率往往带来的计算开销难以转化为显著的性能提升。
除了分辨率之外,模型容量(包括参数量和计算量)对性能提升贡献突出。近期研究通过在相同计算预算前提下,调整图像分辨率和输入信息量,验证了性能提升多数源自计算能力的提升,而非高分辨率带来的额外信息。因此,与其盲目追求极高分辨率,不如结合任务需求合理分配计算资源,从而实现效率与效果的最佳平衡。 针对高分辨率处理的瓶颈问题,局部自注意力机制成为优化ViTs的利器。该方法将输入图像划分成多个非重叠窗口,局限每个token只关注其所在窗口内的其他token,从而将二次方复杂度降低到线性增长,有效缓解了显存和计算负担。著名的ViTDet和UViT模型采用这种策略,配合预训练和窗口尺寸设计,实现了在高分辨率条件下依然保持快速性能和较低内存占用。
更重要的是,这些改进几乎不影响模型表现,使得ViTs在实际应用中更具性价比。 此外,有趣的是,一些现代图像处理框架及方法更偏向采用ViTs。例如,基于ViT的Masked AutoEncoders(MAE)利用非重叠图像块实现了创新的部分输入丢弃策略,极大提升自监督学习效率和效果;CLIP模型中使用ViT编码器往往优于传统的CNN编码器;某些基于自监督学习的方法在ViT架构下表现更为出色。这些都体现了视觉变换器架构特有的灵活性和潜在优势。 实际应用场景中,选择ViT还是CNN应综合考量。CNN在许多传统视觉任务具有良好表现,成熟的生态和优化手段使得其在低端硬件和部分嵌入式设备仍有优势。
ViTs则凭借简洁结构、较好扩展能力和现代硬件支持下的快速推理,正逐步赢得更多开发者青睐,尤其是在需要大规模预训练、丰富上下文捕获或自监督学习的任务上显得更加突出。 展望未来,随着硬件技术和深度学习框架持续进化,ViTs与CNN之间的性能差距有望进一步缩小,甚至超越。持续优化的局部自注意力、动态token丢弃、混合架构设计等创新技术为解决高分辨率处理瓶颈提供了新的思路和可能。同时,针对不同应用场景的定制化设计也将成为主流,强调效率、准确度与资源消耗的平衡。 综上,视觉变换器作为计算机视觉领域的重要架构,已经证明其具备良好的扩展性和速度优势,在至少1024×1024像素分辨率范围内表现稳定且高效。与此同时,合理设定图像分辨率,不盲目追求极高精度,结合具体数据特征与任务需求,才是提升模型性能的关键。
随着更多创新技术的引入和实战经验的积累,ViTs与CNN将持续携手推动视觉智能迈向更高水平,为图像理解和分析提供更强大、更高效的技术保障。