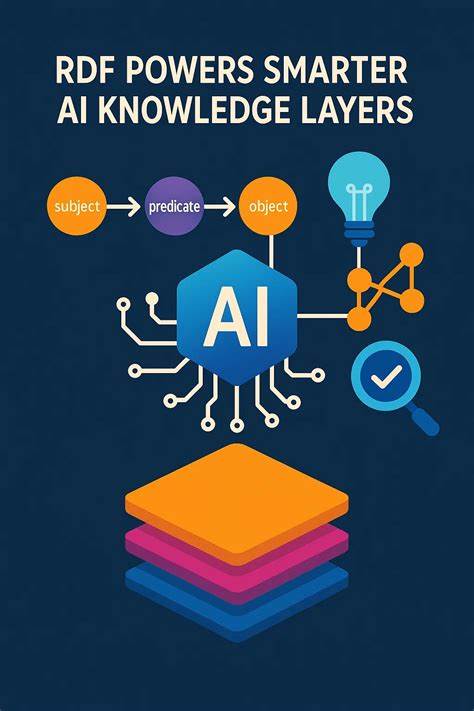
在人工智能迅速发展的今天,数据的有效管理和理解成为制约智能系统性能的关键瓶颈。尤其是大型语言模型(LLM)虽然在自然语言理解方面展现出强大能力,但当面对复杂企业数据库中的海量结构化数据时,准确性和上下文理解能力明显不足。这背后不仅是技术难题,更是知识表达层次选择的根本问题。资源描述框架(RDF),作为构建知识图谱的核心标准,以其独特的知识表示方式成为AI系统自然的知识层,能够有效解决大型语言模型在企业级数据整合与应用中的痛点。 RDF的优势首先体现在其表达自然语言事实的能力。传统的关系型数据库以表格方式存储信息,强调存储效率和数据规范化,但这种"表格化"的模式无法直接对应人类思维中以实体和关系为核心的知识结构。
LLM面对数据库的SQL模式时,必须通过推测不同字段和外键的含义来理解数据,容易产生认知偏差和错误答案。反观RDF通过三元组(主语-谓语-宾语)的格式,直观地模拟了自然语言中主谓宾的句子结构,使得知识表达简洁且具备明确的语义关联,极大降低了AI推断时的歧义性。 身份识别问题是知识图谱构建过程中最为棘手的挑战之一。不同系统中同一实体常被以不同表示方式记录,例如客户编号、员工姓名或产品ID存在多种格式和编码,这极大增加了数据整合的复杂度。RDF通过采用国际资源标识符(IRI)机制,实现了全球唯一且可解析的标识符体系,能够明确区分数据中的不同实体,避免了重复和混淆。IRI不仅具备互联网地址的层级结构,还支持多语言字符编码,满足企业在全球范围内多样化数据的统一管理需求。
企业往往试图通过建立自定义的映射表和身份解析服务来解决实体统一问题,但实践证明这不仅消耗巨大的开发和维护资源,还难以覆盖不断变化和扩展的数据场景。众多领先企业如Uber和Neo4j最终都选择采用RDF技术,避免了重复发明轮子的高昂代价。RDF的开源标准和广泛社区支持为企业提供了成熟可靠的构建框架,加速知识图谱的搭建与运用。 强化大型语言模型应用的关键在于提升模型对知识的连接能力和上下文理解。知识图谱利用RDF展现出显著优势,它不仅让模型明确知道"谁是谁",还能直接描述实体之间的关系,从而使AI能够像人类一样沿着知识链索引信息,极大降低了推理错误的可能性。这种明确的语义连接是人工智能实现智能推理、事实校验和内容生成的基石。
此外,知识图谱结合RDF的可扩展性和灵活性,支持跨部门、跨系统乃至跨企业的数据融合,形成无缝的知识网络。LLM在这样连续和高质量关联的知识层中运行,能够处理更复杂的业务场景,实现自动化问答、决策支持和知识发现等场景的升级。更重要的是,RDF的设计理念鼓励数据的开放、互联和再利用,符合现代企业数字化转型和生态协同的核心趋势。 RDF不仅仅是一个知识表示标准,更是AI系统构建智能知识层的天然选择。它直接响应了数据语义不一致、实体识别模糊和跨域数据整合难题,用统一的语义语言描绘复杂世界的知识图景。企业在选择搭建知识图谱的过程中,避开自定义封闭方案,拥抱RDF,将获得更快的开发效率、更高的准确率和更好的系统可维护性。
从长远来看,随着AI和大数据的深度融合,基于RDF的知识层将成为智能系统发展的基础设施,推动智能服务走向更高的智能化、可靠性和解释性。选择RDF,不仅是技术的选择,也是面向未来数据生态和AI智能化演进的战略决策。大型语言模型的未来,离不开RDF赋能的知识图谱这个自然的知识层,它是实现智能革命的助推器和基石。随着越来越多的企业认识到这一点,基于RDF的知识图谱将在AI领域扮演无可替代的核心角色,推动人工智能技术走入更广阔和深刻的应用场景。 。