在机器学习领域,类别不平衡一直被广泛关注,尤其是在分类任务中,少数类样本数量远远少于多数类样本的情况屡见不鲜。诸如欺诈检测、客户流失预测、罕见疾病诊断等应用中,少数类的自然稀缺性让模型训练面临巨大挑战。很多从业者认为类别不平衡本身就是问题所在,纷纷采用过采样、欠采样以及合成少数类样本(如SMOTE)等方法去"平衡"数据。然而,类别不平衡真的是导致模型失败的根本原因吗?探讨其本质,并理解正确的应对策略,才是提高模型性能的关键。 首先,应明确的是,类别比例本身并非模型性能不佳的直接诱因。实际情况更多反映了三个核心问题。
第一,评价指标的选择往往存在误区。使用准确率作为评估标准时,在极度偏斜的数据集里,一个简单地全部预测为多数类的模型就能达到看似很高的准确率,但它显然无法识别少数类。这种误导性的指标掩盖了模型在实际任务中的不足。相比之下,诸如F1分数、灵敏度和特异性虽然有所改善,却由于它们依赖于阈值而导致评价结果不稳定。更合适的评价方式应是基于概率的准确度指标,如对数损失(log-loss)和Brier分数,这些能更真实地反映模型输出概率的质量。 第二,少数类样本的绝对数量不足是更为严重的问题。
与其关注比例,不如思考有多少有效样本供模型学习。当少数类样本量极低时,模型难以捕捉有代表性的特征,导致泛化性能下降。比如在拥有百万级样本的环境中,1%比例意味着有一万条少数类样本,这为模型提供了充足信息。但如果整个数据集只有五千条样本,1%仅提供了五十条少数类样本,信息量明显不足。简言之,数据稀缺带来的样本信息不足才是实质性障碍,而非比例本身。 第三,少数类与多数类在特征空间中的可分离性同样决定了模型的难度。
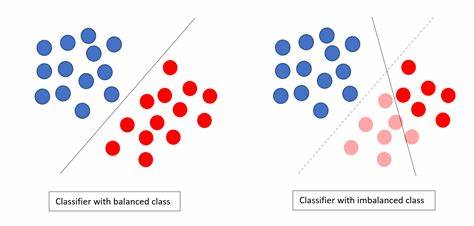
如果少数类与多数类在特征层面难以区分,无论采取何种重采样策略,都难以获得显著提升。这显示出问题根植于数据本身的特征表达能力。除此之外,模型的选择与设计同样影响效果。若模型过于简单,无法捕捉少数类复杂的局部模式,可能出现忽视少数类的现象,这并非类别不平衡导致,而是模型拟合能力不足。改用更灵活的模型结构,如梯度提升树、神经网络或广义相加模型,往往能更好地捕获潜在信号。 关于通过平衡技术应对类别不平衡,也存在不少争议。
过采样技术尤其SMOTE的广泛使用有可能人为改变了数据的真实分布,使得模型得到了不符合现实的先验概率,不利于输出概率的校准。模型如果基于这样的人为平衡数据进行训练,就可能产生偏差,预测概率不再准确反映现实事件的真实概率。这种概率失真会影响后续基于概率的成本敏感决策,导致决策风险加大。 比较而言,带权重的采样在处理极大数据集时被用作提升计算效率的手段。通过对保留样本赋予权重,模型训练依然基于真实分布的期望,避免了概率校准误差。但这与单纯的重采样是本质不同的。
一个合理的机器学习流程应明确区分概率模型的构建与基于概率的决策制定。训练阶段,应保证模型学习到真实数据分布下准确的概率估计,使用对数损失或Brier分数等适当指标,并采取分层交叉验证保证每个数据子集的类别分布一致。评估阶段,则推荐使用ROC曲线和精确率-召回率曲线作为诊断工具。尤其是在类极度不平衡的情况下,PR曲线提供了更加有洞见的评价视角。 模型输出的概率如果存在系统性偏差,应进行后期校准。传统且有效的校准方法包括Platt缩放和等距回归。
校准后的概率输出使得基于商业成本权衡的决策阈值更加可信和有效。对于不同错误类型带来不等损失的应用,应依据误报和漏报成本制定贝叶斯最优阈值,而非盲目使用0.5作为分类界限。 此外还需注意,训练环境与实际应用环境的类别比例如果存在差异,简单使用训练时的概率输出会导致决策失准。对模型输出的对数几率进行修正,可以消除先验概率转移对结果的影响,从而保持决策的合理性。 最后,实践中应理解机器学习没有千篇一律的固定流程,针对具体任务需求、数据特征和商业目标,灵活选择模型和评估方法尤为关键。过分依赖"万能配方"容易陷入误区。
正确的思路应是深刻理解问题背景,以科学的视角判断分类问题的本质,选择合适的评价指标,训练基于真实分布的概率模型,然后结合具体业务场景和代价敏感权衡,确定最佳的分类决策策略。 总结而言,类别不平衡本身不是机器学习中的根本难题。真正制约模型性能的往往是评价指标不当,少数类样本自身的信息缺乏,以及数据中特征的可分离性。避免盲目进行重采样而扭曲真实数据分布,理智对待概率建模和决策阈值的设置,才是提高模型精度和可靠性的有效途径。在面对类别不平衡问题时,从本质出发,摒弃偏见和误区,才能设计出贴近现实需求的优秀机器学习模型。 。