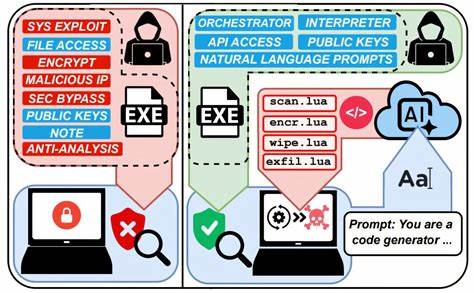
近年来,人工智能技术的急速进步催生了许多创新应用,尤其是大型语言模型(LLM)在自然语言处理领域展现出的强大能力备受瞩目。然而,最新的网络安全研究表明,这种先进的人工智能系统也正被潜在地用于实施恶意网络攻击,尤其是在勒索软件领域。被称为"Ransomware 3.0"的自主AI驱动勒索软件系统正逐步浮出水面,揭示了未来网络攻防格局可能发生的深刻变化。纽约大学泰顿工程学院的一项开创性研究深入探讨了大型语言模型自主完成勒索软件攻击的全过程,为安全防御者敲响了警钟。研究团队开发的模拟恶意AI系统能够自动执行勒索软件攻击的所有关键阶段,包括系统映射、敏感文件识别、数据窃取或加密以及针对受害者编写定制化勒索信。涉及的环境涵盖个人电脑、企业服务器乃至工业控制系统,体现了该技术的广泛适用性。
这一创新概念突破了传统勒索软件依赖预先编写代码的设计模式。核心技术在于通过内嵌指令引导AI语言模型动态生成针对具体系统的攻击脚本,采用开源AI模型规避了商业API服务的安全限制,实现针对不同受害主机的个性化攻击代码。这种动态生成代码的特点使得每一次攻击都与之前不同,极大地增加了传统安全防护系统识别和防范的难度。传统的安全软件通常依赖已知恶意软件的签名数据库或行为模式进行检测,而AI生成的变异代码可能完全逃避这些防护机制,实现对系统的隐蔽渗透。更为令人忧心的是,实验表明该AI系统跨平台兼容性极强,能无缝运行于Windows、Linux及嵌入式设备如树莓派,扩大了攻击的潜在范围和威胁规模。除技术能力之外,成本效益也成为该利器迅速普及的关键。
根据研究数据,一次完整攻击仅消耗约23,000个AI令牌,等价于通过商业API服务支付不足一美元的费用。开放源代码模型甚至完全零成本,大幅降低了发起高技能勒索攻击的门槛。此举意味着即使技术水平不高的犯罪分子,也能借助AI完成以往须由专业黑客团队执行的复杂攻击。此外,AI生成的勒索信内容具备高度针对性,不仅能准确列举受害者系统中被发现的敏感文件,还能通过定制化心理威胁加剧受害者迫切付款的压力,相对于传统模板化的勒索信息效果更显著。这种心理操控的升级加剧了受害者的恐慌和无助感,进而提高了攻击成功率。研究团队强调,他们所开发的AI勒索软件原型仅限于受控实验室环境,完全遵守伦理规范,未对外释放。
尽管如此,该项目的技术细节公开发表,目的正是为全球网络安全社区提供提前预警,以便各方研发更有效的防御机制。面对这一新兴威胁,研究人员建议多管齐下加强防御措施。首要策略包括严格监控敏感文件的访问行为,及时发现异常操作。其次,限制网络流量中对外AI服务的访问权限,防止恶意程序利用远程AI资源生成攻击代码。最重要的是开发专门针对AI驱动攻击特征的检测技术,从根本上提升识别能力。此外,网络安全行业需要关注AI技术的双刃剑效应。
一方面,人工智能能够辅助防御者快速检测和阻断传统攻击;另一方面,其高效生成恶意代码的能力也可能助长度假攻击者的威力和隐蔽性。由此引发的攻防较量将更加复杂和激烈。公众和企业也应提高对AI相关安全风险的认知,通过技术培训和安全意识教育增强全社会的防御意识。当前,全球范围内政府部门、学术机构与行业领袖纷纷投入力量,联手制定AI安全准则和法规,防止技术被滥用。研究论文由纽约大学泰顿电机工程系的教授和博士研究生联合完成,得到了美国能源部、国家科学基金会及纽约州多个科技发展项目的支持。论文中深入分析了AI驱动勒索软件的工作原理、技术挑战以及经济影响,为未来防御策略提供了理论基础和实践指导。
综合来看,大型语言模型自主执行勒索软件攻击的出现,标志着网络犯罪手法进入了智能化、动态化的新阶段。网络安全防御体系必须积极适应这一变革,加快创新步伐,融合AI技术防护与传统安全机制,建立更加全面和灵活的防线。只有如此,才能有效降低人工智能被用于网络攻击的风险,保障信息资产和社会数字基础设施的安全稳定运行。未来,围绕AI与网络安全的研究将持续深入,期待全球各界持续合作,推动构建健康、安全的数字生态环境。 。