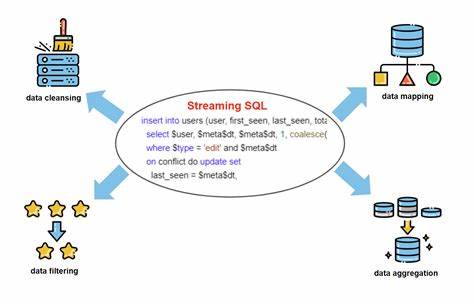
随着大数据时代的到来,企业和研究机构对于实时数据处理和智能分析的需求日益增长。传统的批处理方式难以满足对时效性和精准性的双重要求,数据科学家和工程师迫切需要一种既高效又灵活的方法来处理海量数据,并在此基础上构建复杂的机器学习和人工智能模型。流式SQL(Streaming SQL)正是在这样的背景下应运而生,成为连接数据采集、处理和智能分析的桥梁,推动了实时AI与机器学习的快速发展。 流式SQL是一种扩展了传统SQL功能的数据流处理技术,通过持续不断地查询和转换数据流,实现对动态数据的实时监控和分析。它的出现极大地降低了流式数据操作的门槛,使更多非程序员能够利用SQL的熟悉语法,自如地构建高性能的实时数据应用。然而,尽管SQL在结构化数据查询方面表现优异,但在复杂逻辑处理、机器学习模型的训练和部署方面却存在较大限制。
为弥补这一短板,最新的技术趋势是将SQL与Python深度融合,利用Python用户自定义函数(UDF)增强流式SQL的能力。 Python作为数据领域最受欢迎的编程语言之一,拥有丰富的机器学习、深度学习和数据处理库,如Scikit-learn、TensorFlow、PyTorch及Hugging Face等。通过Python UDF,开发者可以将这些强大的库直接嵌入到流式SQL查询中,实现对实时数据的智能分析与预测。这不仅简化了数据科学项目的架构设计,避免了跨系统繁琐的数据传输,还能充分发挥SQL高效的数据检索优势与Python灵活智能化处理能力的互补优势。 在实际应用中,流式SQL平台通过支持Python UDF实现了实时机器学习模型训练与推断的闭环流程。数据科学家可以使用SQL语句对流数据进行清洗、特征提取和转换,有效准备机器学习的输入特征。
同时,利用Python UDF调用Scikit-learn等库,可在线训练分类、回归或聚类模型,并将训练好的模型存储为本地文件或内存状态。随后,另一个Python UDF函数在实时数据流中执行快速推理,将新数据输入训练模型,获得预测结果,实现线上实时智能决策。这种"一站式"解决方案极大地简化了传统机器学习应用的部署复杂度,提升了实时性和业务响应速度。 时间序列预测作为许多行业核心的业务需求,同样受益于流式SQL与Python UDF的结合。通过对历史时间序列数据的稳定回放和实时重放,结合基于ARIMA、Prophet或深度学习模型的统计与机器学习算法,用户能够即时获得趋势预测、异常检测和因果分析结果。例如,将统计模型ARIMA封装为Python聚合函数,实时处理并预测未来数据变化,帮助金融、供应链及气象等领域实现智能预警和资源优化。
深度学习的引入为流式数据带来更强大的理解与应用能力。借助PyTorch或TensorFlow框架构建的神经网络,不仅能够识别复杂的多维特征关系,还能实现对图像、语音和自然语言等非结构化数据的智能处理。例如,应用LSTM模型进行长序列时间序列分析,或者借助Transformer架构进行文本情感分析,均可通过Python UDF嵌入SQL流处理流程中,实时提供高质量的AI推理结果。 大规模预训练语言模型(LLM)如GPT系列的兴起,更是为实时数据智能化带来革新。利用Python UDF接口与开源或云端API集成,企业能够将强大的自然语言理解能力无缝嫁接到数据管道中,实现自动化文本摘要、多语言翻译甚至智能问答。借助Agentic框架如LangChain和LlamaIndex,结合流式SQL,构建智能代理在业务流程中自动执行复杂任务也成为可能,大幅提升了企业运营效率与用户体验。
尽管流式SQL结合Python UDF极大拓展了数据平台的功能,但系统设计仍需关注性能优化与资源管理。Python代码执行涉及解释器开销和内存管理,特别是在处理高频、大规模流数据时,合理设计批处理大小、状态管理与异步机制,能有效避免计算瓶颈和延迟。数据平台也应支持模型版本控制、在线热更新以及故障恢复,提高系统的稳定性和可维护性。 总结来看,流式SQL不仅是结构化数据实时查询的强大工具,更通过集成Python用户自定义函数,打破了传统SQL的能力局限,为实时机器学习和AI应用提供了一条简洁而高效的路径。它实现了数据处理与智能分析的深度融合,极大提升了业务洞察的速度和准确性。随着云计算、大数据和AI技术的不断成熟,基于流式SQL的智能数据平台将在金融风控、智能制造、智慧城市、智能客服等诸多领域发挥重要作用,引领数据驱动创新的新潮流。
未来,融合更多开源库和优化算法的能力将进一步丰富这一生态,助力企业构建更加智能、灵活和可扩展的实时AI应用,实现数字化转型的战略目标。 。